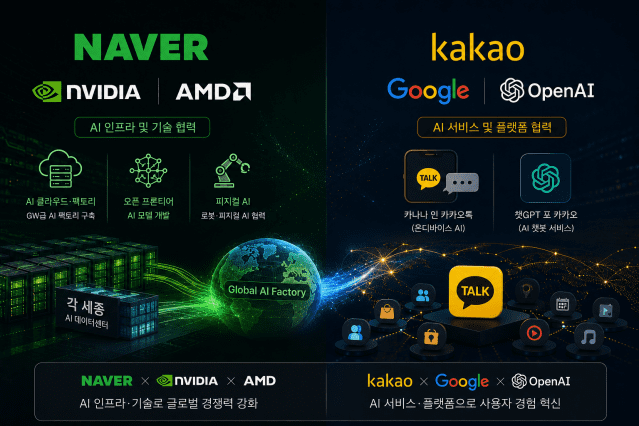
AMD, 국산 NPU 생태계 힘 보탠다...한국에 R&D센터 설립
정부가 AMD와 AI반도체 분야에 맞손을 잡기로 했다. GPU 중심의 AI 컴퓨팅을 넘어 CPU, NPU 등 다양한 방식을 결합하는 이기종 컴퓨팅에 대비하기 위한 것이다. 27일 과학기술정보통신부에 따르면 배경훈 부총리 겸 과기정통부 장관이 리사 수 AMD 회장을 만나 AI 반도체와 컴퓨팅 분야 협력을 위한 양해각서를 체결했다. AMD는 CPU와 GPU를 아우르는 글로벌 반도체 기업으로 2025년 기준 연매출 346억 달러를 기록했으며, 특히 서버용 CPU와 GPU의 수요 증가에 힘입어 데이터센터 사업 매출도 166억 달러에 달하는 등 AI 컴퓨팅 시장의 주요 기업으로 자리매김하고 있다. 특히 오픈소스 소프트웨어 플랫폼인 ROCm과 개방형 표준을 기반으로 AI 컴퓨팅 생태계 확대를 추진하고 있다. 이를 통해 구글, 애플, 마이크로소프트 등 여러 글로벌 기업들과 함께 개방형 초고속 AI 반도체 연결 표준인 UALink 창립 멤버로 참여하는 등 개방형 AI 인프라 생태계 조성에도 적극 나서고 있다. 이기종 AI 컴퓨팅 대비...국산 NPU, AMD와 협력 최근 글로벌 AI 반도체 시장은 생성형 AI와 에이전틱 AI 확산에 따른 추론 수요 증가로, 단일 GPU 중심의 컴퓨팅 구조에서 벗어나 이기종 컴퓨팅 아키텍처로 빠르게 전환되고 있다. AI 서비스 제공 비용을 낮추고 성능과 전력 효율을 최적화하기 위해 워크로드별 최적의 연산자원을 활용하는 방향으로 AI 인프라 경쟁의 중심이 이동하고 있다는 뜻이다. 양해각서는 AI 컴퓨팅 아키텍처 변화에 대응해 AMD의 CPU, GPU와 추론 분야에 강점을 가진 국산 NPU를 연계하는 이기종 AI 컴퓨팅 인프라를 구축하고 국내 AI반도체 생태계의 글로벌 협력 기반을 확대하기 위해 체결됐다. 구체적으로 AMD CPU, GPU와 국산 NPU를 연계한 이기종 AI 컴퓨팅 인프라 구축과 실증을 추진한다. 이를 통해 AI 서비스별 특성에 맞춰 다양한 연산자원을 효율적으로 조합 활용하는 통합 컴퓨팅 환경을 구현하고 AI반도체 기업뿐 아니라 메모리, DPU, CXL, 네트워크, 서버, 오케스트레이션 소프트웨어 등 관련 국내 기업들이 함께 참여하는 개방형 AI 컴퓨팅 생태계를 조성한다. 이를 기반으로 국산 AI반도체가 글로벌 AI 컴퓨팅 공급망에 참여할 수 있도록 실질적인 레퍼런스 모델을 확보해 나갈 계획이다. AMD, 한국에 AI 연구센터 설립 양측은 국가과학AI연구센터(NAIS)를 중심으로 'AI for Science' 연구 협력을 추진한다. 첨단 과학기술 분야의 AI 기반 연구와 도전적 연구개발을 뒷받침하기 위해 AMD는 CPU와 GPU 등 고성능 컴퓨팅 자원과 AI 소프트웨어, 전문 인력 등을 제공할 계획이다. AMD는 국내에 인공지능 우수 연구센터(AI Center of Excellence) 설립을 추진한다. 인공지능 우수 연구센터는 AMD의 AI 컴퓨팅 자원과 소프트웨어 역량을 기반으로 국내 기업, 대학, 연구기관의 기술 협력을 비롯해 AI 반도체 소프트웨어 개발, 컴퓨팅 기술 검증 및 공동연구를 지원하는 협력 거점 역할을 수행할 예정이다. 이를 통해 AMD의 글로벌 네트워크와 국내 산학연 역량을 유기적으로 연계해 개방형 AI 생태계를 기반으로 한 다양한 협력 기회를 확대해 나갈 계획이다. AI 분야 우수 인재 양성을 위해서도 협력한다. AMD는 국내 주요 대학교와 대학원에 AI 컴퓨팅 플랫폼 기반의 교육 연구 프로그램과 컴퓨팅 자원을 지원하고, 국내 학생과 교수, 연구자들이 최신 AI 기술과 글로벌 개발 환경을 경험할 수 있는 기회를 확대해 나갈 예정이다. 이밖에 피지컬 AI 등 차세대 AI 분야의 공동연구와 기술 협력을 추진해 미래 AI 기술 경쟁력 확보를 위한 산학연 협력 기반을 확대해 나갈 예정이다. 과기정통부와 AMD 간 협력은 지난 3월 AMD 리사 수 회장의 방한으로 논의가 본격화됐으며, 이후 양측 간 긴밀한 협의를 거쳐 협력 분야와 실행 방안을 구체화해 왔다. 양해각서 체결식은 리사 수 회장의 초청으로 추진돼 글로벌 AI 생태계 변화에 대응하기 위한 양측의 전략적 협력 의지를 다시 한번 확인하는 계기가 됐다. 배경훈 부총리는 “글로벌 AI 경쟁은 CPU, GPU, NPU 등 다양한 연산자원을 결합하는 이기종 컴퓨팅과 개방형 생태계 중심으로 변화하고 있다”며 “대한민국이 AI 3대 강국으로 도약하기 위해서는 자립적이면서도 개방적인 AI 컴퓨팅 인프라 기반 확보가 중요하다”고 밝혔다. 이어 “AMD와의 협력을 통해 국내 AI반도체 생태계의 경쟁력을 높이고, 글로벌 AI 컴퓨팅 인프라 변화에 대응하는 새로운 협력 모델을 만들어 갈 수 있을 것”이라고 말했다. 한편, AMD의 리사 수 CEO는 "한국은 반도체와 AI, 첨단 연구, 피지컬 AI 분야에서 세계적인 경쟁력을 갖춘 AMD의 핵심 전략 시장"이라며, "AMD는 과학기술정보통신부와 협력해 고성능 컴퓨팅 기술과 개방형 소프트웨어 역량, 글로벌 생태계 파트너십을 결합함으로써 대한민국이 개방형·이기종 AI 인프라를 구축할 수 있도록 적극 지원할 것"이라고 말했다. 이어 "이번 협력은 단순한 하드웨어 지원을 넘어 기술 협력과 인재 양성, 긴밀한 공동 연구개발을 통해 대한민국의 AI 혁신과 경제 성장에 기여하겠다는 AMD의 장기적인 의지를 보여주는 것"이라고 밝혔다. 양 기관은 이번 협약의 실질적인 이행을 위해 공동 협의체를 구성하고, 분기별 실무회의를 통해 세부 협력 과제와 추진 방안을 지속적으로 협의해 나갈 예정이다.