KAIST 석사과정 AI에이전트로 주식 자동매매…수익률은
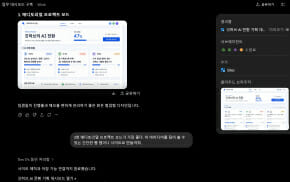
KAIST 연구생들이 AI 에이전트 오픈클로를 이용해 자동 주식매매를 했다. 과연 수익률은 어땠을까? 이관택 전기및전자공학부 석사과정 연구생이 220만원을 투자해 실제 투자해봤다. 이틀간 350건 자동매매한 결과는 2만5,029원 손실. 매수금액 대비 -1.11% 손실을 입었다. KAIST 테라랩(김정호 전기및전자공학부 석좌교수 연구실, 랩장 서해석 박사과정생)이 지난 3일 오픈클로 AI에이전트를 HBM(고대역폭메모리) 등 연구 현장에 적용한 실험이나 일상 적용 실험 결과를 공개하는 워크숍을 진행했다. 석, 박사과정 연구생 총 14명이 오전 8시부터 12시 40분까지 예정 시간을 40분가량 넘겨 오픈클로를 연구비서로 활용한 사례 및 시연 7건과 일상비서로 활용한 사례 및 시연 6건을 각각 20분씩 발표했다. 이 워크숍에서 10번째 발표자로 나섰던 이관택 연구생은 "반복적인 단기 매수·매도 과정에서 수수료와 세금 등 거래비용이 2만 1,113원 발생했다"면서 "개인이 AI만으로 완전 자동매매를 하는 것은 한계가 있다는 결론"이라고 말했다. 이관택 연구생은 "실제 NH농협 오픈API를 이용해 실계좌를 연동하고, 국내 시장 한정으로 운영했다"며 "명령은 텔레그램을 통해 입력했다. 오픈클로가 증권사 API를 통해 시세나 잔고, 주문, 체결상태를 확인하는 방식"이라고 설명했다. 이 연구생은 "특정 종목으로 거래를 한정하거나 거래횟수 제한, 최소 주문금액 설정, 고변동성 종목 필터링 등을 고려한 조건 등을 더 세밀히 고려한 거래가 필요하다고 느꼈다"며 "자동매매 보다는 AI 투자 보조 도구로 활용하는 것이 더 현실적일 것 같다"고 부연설명했다. 일상비서로의 활용 케이스에서 이승재 석사과정 연구생은 오픈클로를 기반으로 포트폴리오 관리 에이전트(알파클로) 사용 결과를 공개했다. 알파클로는 자산 리스크 관리에 초점을 맞춰 의사결정을 지원하는 에이전트다. 이외에 일상비서 에이전트 사례로 박준호·김태현·김병목 ·배재근 연구생이 논문 키워드 자동수집, 발표자료 초안생성, 멀티-에이전트 역할 부여·리눅스 서버 관리 등의 에이전트 활용 결과를 선보였다. 이에 앞서 연구비서로서의 AI 에이전트에서는 이현이·김근우·서해석·안현준·양채민·이정현·신하겸·윤영수 연구생 및 박사가 나서 반도체 패키지 설계 및 해석, PDN 시뮬레이션, 이퀄라이저 최적화, HFSS EM 시뮬레이션 자동화, SIPI 지식 베이스 구축, 협업 채팅방 시연, 패치 안테나 자동설계 사례 및 사용 결과를 공개했다. 이정현 연구생(박사과정)은 "AI 에이전트를 연구 현장에 비서처럼 적용해 보면서, 단순히 질문에 답하는 챗봇을 넘어 실제 연구 업무의 반복적인 과정을 대신 수행할 수 있다는 가능성을 확인했다"며 "예를 들어 논문 PDF를 넣으면 알아서 문서를 확인하고, 마크다운으로 변환하고, 핵심 개념과 용어를 정리해서 연구용 지식 베이스 형태로 만들어주는 과정을 오픈클로가 단계적으로 수행했다"고 설명했다. 이 연구생은 "사용자는 텔레그램으로 작업을 지시하고 진행 상황을 확인하기만 하면 되기 때문에, 자료 정리나 문헌 관리에 들어가는 시간을 줄이고 연구자는 해석과 판단에 더 집중할 수 있다는 점에서 연구 효율 향상에 대한 기대가 크다"고 말했다. 김태현 연구생(석사과정)은 "AI 에이전트를 일상에 적용할 수 있는 다양한 방법들에 대해 공부하고 적용해 보면서, API 제공 유무와 관계없이 존재하는 대부분의 프로그램에 적합한 방법을 적용해 활용할 수 있음을 확인했다"라며 "자료 조사, 문서 작성 등 연구를 제외한 부가 업무를 보조하도록 구성한다면 연구 생산성 향상에 기여할 수 있을 것"으로 예상했다. 이번 워크숍은 전, 후반부로 나눠 진행한 이번 워크숍에서 전반부는 반도체 패키지 설계, 전원무결점성 분석, 데이터셋 생성, 시뮬레이션 자동화, 지식베이스 구축 등 연구 업무 자동화 사례를 주로 다뤘다. 후반부는 포트폴리오 관리, 자동 주식 매매, 논문 검색, 캘린더 기반 발표자료 생성, 멀티 에이전트 협업, 서버 관리 등 일상·연구 보조 사례를 발표했다. SK하이닉스 입사가 예정된 김근우 박사후연구원은 "핵심은 AI가 단순히 답변하는 것이 아니라, 실제 도구를 실행하고 결과를 다시 보고하는 실행형 연구 비서로 동작할 수 있는지를 확인했다"며 "AI 에이전트를 단순 챗봇이 아니라, 반도체·패키지 설계 툴을 실제로 다루는 연구 보조자로 구현했다는 점에 주목해달라"고 주문했다. 김정호 석좌교수는 최종 마무리에서 "평소 목말라하던 아이템을 다뤘다는데 특히 의미가 있다. 모두 재미난 아이템"이라고 평가하며 "오는 11월께는 니모클로 등을 활용한 워크숍, 내년 초에는 HBM과 HBF(고대역폭플래시메모리)를 주제로 한 워크숍을 검토해 보자"고 덧붙였다. 워크숍 발표 내용은 6일 오전 6시 테라랩 홈페이지(http://tera.kaist.ac.kr)를 통해 공개한다.