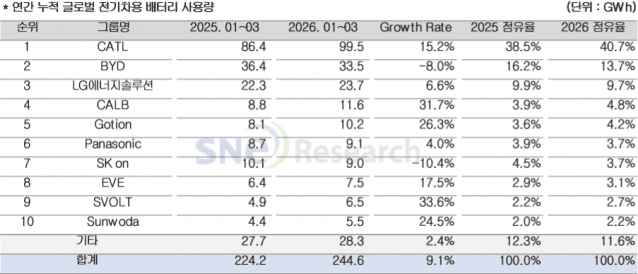
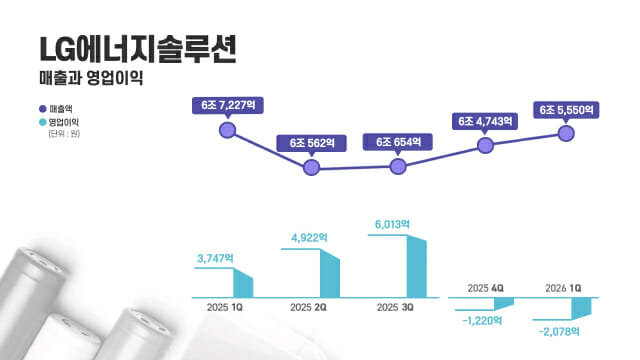
[ZD브리핑] 기름값 묶자 소비 늘었다?…최고가격제 '연장 논쟁'
지디넷코리아는 IT 업계의 이슈를 미리 체크하는 '이번 주 꼭 챙겨봐야 할 뉴스'를 제공합니다. '꼭 챙길 뉴스'는 정보통신, 소프트웨어(SW), 전자기기, 소재부품, 콘텐츠, 플랫폼, e커머스, 금융, 디지털 헬스케어, 게임, 블록체인, 과학 등의 소식을 담았습니다. 바쁜 현대인들의 월요병을 조금이나마 덜어 줄 '꼭 챙길 뉴스'를 통해 한 주 동안 발생할 IT 이슈를 미리 확인해 보시기 바랍니다. [편집자주] 삼성전자 1분기 '역대급 실적'…반도체 웃고 스마트폰 울었다 삼성전자의 지난주 1분기 실적발표로 사업부별 온도차가 확인됐습니다. 메모리 반도체 수요 강세로 1분기 역대 최대 분기 실적을 올렸지만, 스마트폰과 TV 등을 만드는 DX 부문 영업이익은 전년 동기보다 줄었습니다. 스마트폰(MX) 사업부는 수년간 매 분기 공개했던 분기 스마트폰과 태블릿 출하량, 스마트폰 ASP를 공개하지 않았습니다. 메모리 가격 급등은 반도체 부문에 호재이지만, DX 부문에는 수익성 하락 요인입니다. 노조 총파업도 변수입니다. 삼성그룹 초기업노동조합 삼성전자 지부는 성과급 상한제 폐지 등을 요구하며 이달 21일부터 18일간 총파업을 예고한 상황입니다. 데이터센터와 서버 관련 부품 수요도 여전히 강세였습니다. MLCC 세계 1위 일본 무라타제작소는 지난 2025회계연도(2025년 4월~2026년 3월) 역대 최대 실적을 올렸고, 2026회계연도(2026년 4월~2027년 3월)에도 역대 최대 실적 경신을 예고했습니다. 무라타는 "2026회계연도에 서버용 MLCC 매출이 전년비 85~90% 늘어날 것"이라고 기대했습니다. 삼성전기도 데이터센터용 MLCC 수요 강세를 강조한 바 있습니다. 삼성전기는 "2분기 MLCC 수요는 전 응용처에 걸쳐 1분기보다 상승을 예상한다"고 밝혔습니다. “기름값 묶었더니 소비 폭증?…최고가격제 '연장 vs 폐지' 격돌 지난달 24일부터 적용된 4차 석유 최고가격제가 오는 7일 만료를 앞둔 가운데, 제도 지속 가능성을 두고 여러 전망이 오갑니다. 앞서 가격 제한에 따른 정유사 손실을 정부가 사후 보전하겠다고 밝혔는데, 이 손실을 계속 누적하기엔 재정 부담이 커지기 때문입니다. 최고가격제 시행이 오히려 고유가 상황임에도 석유 소비를 부추긴다는 지적도 만만치 않습니다. 정유업계 손실 산정 방식을 두고 정부와 업계 입장차도 큰 상황입니다. 업계는 국제유가를 기준으로 제시하는 반면, 정부는 보다 정밀한 원가를 업계가 제안해야 한다고 보고 있습니다. 도널드 트럼프 미국 대통령이 이번주부터 유럽연합(EU)산 승용차와 트럭에 대한 관세를 25%로 인상하겠다고 밝혔습니다. 미국과 EU는 지난해 새로운 무역협정을 체결하면서 미국으로 수입되는 승용차와 트럭에 대한 품목별 관세를 당초 25%에서 15%로 낮추기로 합의했지만, 이를 10%포인트 인상해 원상복구하겠다는 것입니다. 미국과 서유럽 동맹국들의 군사동맹인 북대서양조약기구(NATO·나토) 주요 회원국들이 미국의 중동 전쟁 파병 요청을 사실상 거절하고, 이에 대해 트럼프 대통령이 불만을 토로해온 것과도 무관치 않다는 분석이 나옵니다. 통신사 1분기 실적 발표 시작 국내 주요 통신 미디어 기업의 1분기 실적 발표가 시작됩니다. 먼저 오는 7일에는 SK텔레콤과 LG유플러스가 같은 날 실적을 발표합니다. SK텔레콤은 지난해 하반기 집중된 침해사고 수습 비용을 털어낸 성적표가 예상되고, LG유플러스는 경쟁사의 위약금 면제 시기에 끌어모은 가입자를 통한 매출 성장이 주목할 부분입니다. 같은 날 CJ ENM의 실적 발표도 예정돼 있습니다. 8일에는 KT스카이라이프가 실적을 발표할 예정입니다. 내달 지방선거를 앞둔 상황에서 과학기술 ICT 입법 논의도 지속됩니다. 7일 과학기술정보방송통신위원회는 전체회의를 열어 법안의결을 계획하고 있습니다. 법안 상정은 법안심사소위원회 결과를 따를 것으로 보입니다. 앞서 6일 ICT 분야 법안 심사 회의를 개최합니다. 국내외 기업, 1Q 실적 잇따라 공개...팔란티어•안두릴, 전략 발표 주목 현대오토에버는 오는 4일 2026년 1분기 실적 발표 컨퍼런스콜을 진행합니다. 해당 분기 현대오토에버 매출은 전년 동기 대비 13% 증가한 9357억원을 기록했습니다. 현대차그룹 디지털 전환 가속화 사업 확대가 성장을 견인하며 역대 1분기 매출 최고치를 거뒀습니다. 다만 미국관세 영향과 고객사 일부 계약 시점이 2분기 이후로 조정되며 영업이익은 20.7% 줄어든 212억원을 기록했습니다. 소프트웨어 중심 차량(SDV) 대응을 위한 선행 투자 등으로 수익성은 감소했으나 중장기적 성장 기회를 발굴한다는 방침입니다. 팔란티어는 같은 날 2026 회계연도 1분기 실적을 발표합니다. 주요 플랫폼 'AIP'가 실제 기업 현장에서 어떻게 AX를 구현하고 있는지가 이번 발표 핵심입니다. 마키나락스는 이달 6일 서울 영등포구 63빌딩에서 기업공개(IPO) 기자간담회를 개최합니다. 이번 행사는 올해 AI 기업 상장의 첫 포문을 여는 마키나락스가 새로운 모멘텀을 앞두고 성장 여정을 공유하는 자리로 마련됐습니다. 마키나락스는 현장 문제를 해결하기 위해 고민해 온 기술력을 바탕으로 자본시장에서 기술력과 시장성을 입증하고 '피지컬 AI 시대'를 앞당기겠다는 계획입니다. 미국 방산 기술 기업인 안두릴 인더스트리는 오는 7일 서울 종로구 포시즌스 호텔에서 안두릴 공동창업자 겸 최고경영자(CEO) 방한 기념 기자간담회를 개최합니다. 브라이언 쉼프 안두릴 CEO는 아시아태평양(APAC)을 비롯한 글로벌 진출 전략을 발표할 예정입니다. 이어서 존 킴 안두릴코리아 대표가 국내 진출 파트너십 현황을 소개합니다. 데이터독과 클라우드플레어는 같은 날 2026 회계연도 1분기 실적발표를 진행합니다. 데이터독은 AI 인프라 복잡성 증가로 옵저버빌리티수요가 급증한 만큼 매출 성장세를 기대하고 있습니다. 클라우드플레어는 엣지 컴퓨팅 기반 AI 추론 서비스 '워커스 AI' 성과에 주목하고 있습니다. 롯데이노베이트도 이날 국내외 기관투자자들을 대상으로 1분기 실적 발표 컨퍼런스콜을 진행할 예정입니다. 1분기 연결기준 영업이익은 97억원을 기록했고, 매출액은 2812억원으로 전년 동기대비 1.3% 감소했습니다. 직전 분기는 60억원 순손실이었으나 올해 1분기에 흑자로 돌아섰습니다. SOOP, '구글 플레이 ASL 시즌21' 8강 2주차 경기 SOOP이 오는 4일부터 '구글 플레이 ASL 시즌21' 8강 2주차 경기를 진행합니다. ASL은 블리자드 엔터테인먼트의 공상 과학 RTS 게임 '스타크래프트: 리마스터'로 진행되는 올해로 11주년을 맞은 e스포츠 리그입니다. 지난 시즌에 이어 이번 시즌 역시 구글플레이가 공식 스폰서로 참여했습니다. 8일 2주차 경기는 4일 오후 7시부터 진행되며, 이날 이제동(Z)과 이재호(T)가 맞붙습니다. 이어 5일 8강 4경기에서는 장윤철(P)과 이영호(T)가 격돌합니다. 앞서 열린 8강 1주차에서는 박상현(Z)과 신상문(T)이 각각 조일장(Z), 윤수철(P)을 상대로 3대0 승리를 거두며 4강에 선착했습니다. 모든 본선 경기는 서울 대치동 프릭업 스튜디오에서 진행되며, 대회 생중계 및 다시보기 등 자세한 정보는 SOOP ASL 공식 방송국을 통해 확인할 수 있습니다. 이와 함께 이번 주에는 넷마블과 넥써쓰 등이 2026년 1분기 실적을 공개합니다. 증권사 실적 추정치를 보면 넷마블은 1분기 매출 6921억원, 영업이익 725억원을 기록했다고 예상됩니다. 이는 전년 대비 매출과 영업이익 모두 개선된 성과입니다. 한국아동복지학회, 8일 2026년 춘계학술대회 한국아동복지학회,는 '아동인구 변화와 지역 격차: 아동복지체계의 대응 전략'이라는 주제로 5월8일 한양사이버대학교에서 2026년 춘계학술대회를 개최합니다. 이번 학술대회는 최근 아동인구 감소와 지역 간 인프라 불균형 심화라는 구조적 변화 속에서, 지역별 아동복지 환경의 격차를 다각도로 조명하고 이를 해소하기 위한 실질적 대응 방안을 모색하고자 마련됐습니다. 특히 강원, 울산, 전북, 충남 등 권역별 사례를 중심으로 아동의 삶의 조건, 서비스 접근성, 지역사회 기반 돌봄 체계의 특성을 비교·분석하며, 각 지역의 다양한 정책적 노력과 현장의 한계를 함께 공유할 예정입니다. 또 지역 간 아동복지 격차가 모든 아동의 동등한 권리 보장이라는 원칙에 반한다는 문제의식 아래, 중앙정부의 역할을 심도 있게 논의하는 라운드테이블도 진행됩니다. 이번 학술대회는 지방선거를 앞두고 아동복지 정책을 주요 의제로 환기시키는 계기가 될 것으로 기대되며, 지역성과 국가책임이 조화된 아동복지체계 구축 방향을 제시하는 중요한 자리가 될 것입니다. 한림대동탄성심병원, '병원체험학교' 참여자 모집 한림대학교동탄성심병원은 5월30일부터 11월28일까지 병원 본관에서 총 6회에 걸쳐 운영하는 '병원체험학교' 참여자를 모집합니다. 대상은 화성·오산·용인·수원·평택·안성 지역 초등학교 4~5학년 학생이며, 회차별 최대 20명을 선착순으로 모집합니다. 프로그램은 ▲병원체험학교 소개 ▲수술실 의료 활동 이해 ▲올바른 손 씻기 체험 ▲우리 몸 속 세포와 인체 구조 탐구 ▲미션 수행 및 수료식 등으로 학생들이 의료 환경을 쉽고 흥미롭게 이해할 수 있도록 구성됐습니다. 이번 프로그램은 코로나19로 잠정 중단됐던 현장체험 활동을 다시 운영하는 것으로, 학생들이 의료 현장을 직접 경험하고 진로를 탐색할 수 있도록 기획됐으며, 특히 참여형 체험 중심으로 구성해 교육 효과를 높였다는 설명입니다. 신청은 매월 1일 오전 9시 QR코드를 통해 가능하며, 1일이 공휴일인 경우 다음 첫 평일에 접수가 진행됩니다. AI 시대, '일'과 '사람' 잇는 기술 이야기....'HR테크 리더스 데이', 7일 개최 AI 전환(AX)이 가속화되는 흐름 속에서 '일'과 '사람', 그리고 이 둘을 잇는 '기술' 중심의 HR 전략을 모색하는 'HR테크 리더스 데이 시즌5'가 7일 서울 선정릉역 슈피겐홀에서 개최됩니다. 이번 행사는 '휴먼테크+휴먼터치(Human Tech+Human Touch)'를 대주제로, 기술은 차갑게 활용하되 인간적인 관계는 뜨겁게 유지하는 조직 성장 기록을 공유합니다. 단순한 솔루션 소개를 넘어 채용, 조직문화, 리더십, 웰니스 등 HR의 핵심 의제를 한자리에서 점검할 수 있는 실전형 컨퍼런스로 기대를 모으고 있습니다. 이번 행사에서는 조여준 더벤처스 CIO·송석호 네이버 리더·오현호 작가·이해민 조국혁신당 의원 등 전문가 명강연이 펼쳐질 예정입니다. 아울러 플렉스, 크리니티, 엔피, 영림원소프트랩, ZUZU, 헤세드릿지, 팀스파르타, 소프트스퀘어드, 링글 등이 HR 관련 성공 사례와 새로운 방향 등을 공유합니다. 특히 AI가 대체할 수 없는 인간 고유의 동기와 몰입, 그리고 데이터 기반의 의사결정이 조직을 어떻게 변화시키는지에 대한 심도 있는 논의가 이뤄질 예정입니다. 현장 참여 등록은 마감됐으며, 온라인 생중계(무료) 참여는 가능합니다.