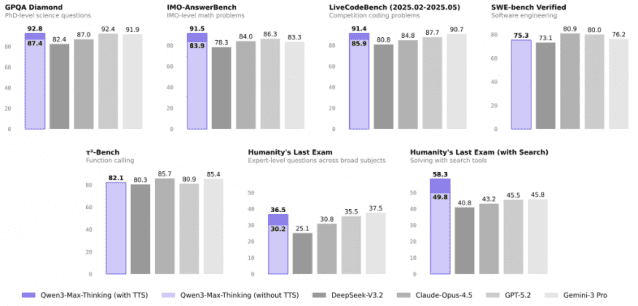
타는 목마름으로 우주와 생명, 한살림을 노래하다
1. IDOL: 타는 목마름 "나는 찢어진 사람입니다." 1987년을 전후로 세평이 극과 극으로 갈리었다. 군사독재 시절 그의 시를 읽으며 부르르 전율했던 이들이, 민주화 이후에는 파르르 분개했다. 살아서는 지독하게 고독했고, 죽어서도 오해가 자욱한 인물이다. 그 김지하를 어떻게 진부하지 않게 회고할 것인가, 어떠하게 그가 남기고 간 저 우주처럼 광대한 말과 글을 미래에 맞춤하여 되살려낼 것인가, 끙끙 골머리를 앓으며 두어 달을 흘려보냈다. 끝내 그의 묘소를 찾아가 꽃 한 송이 바치고 절을 올린 다음에야 실마리가 풀려나갔다. 몸부림과 몸서리, 살풀이를 했다고나 할까. 본디 남도 사람이다. 호남의 바다에서 태어나 강원의 산자락에 묻혔다. 고향은 파도가 일렁이는 목포이고, 무덤은 구비구비 원주에 자리한다. 부모가 지어준 이름은 영일(英一), 한 송이 꽃 봉우리이다. 흰 그늘, 달을 품은 해처럼 한 편의 파노라마 같은 인생을 살았다. 세상은 시대가 부여한 필명 '김지하'로만 그를 기억한다. 하지만 파란만장 일생을 마치고 숨을 거두었을 때, 정작 그의 장례식장을 찾는 이는 드물었다. 한때 동지였던 진보는 싸늘하게 외면했고, 한철 그를 활용했던 보수는 냉담하게 손절했다. 한 시대를 풍미했던 거인의 고별 치고는 더없이 쓸쓸했던 것이다. 게으른 재래식 언론은 재차 저 멀리 반세기 전 1970년대를 환기시키며 지하를 '저항시인'으로 호명했다. 1980년대 이래 옹골차게 추구했던 생명운동가로서의 면모를 싹뚝 삭제한 것이다. 실로 그는 평생을 영일과 지하 사이, 본캐와 부캐 사이에서 혼과 육이 찢겨진 사람이다. 호랑이는 죽어서 가죽을 남기고, 사람은 죽어서 이름을 남긴다 했던가. 정작 영일은 허물을 벗겨내듯 '지하'를 가죽처럼 찢어버리고 싶었다. 살아 생전 명예이자 멍에가 되어 버린 이름을 불태워버리는 화형식을 염원했지만, 죽어서도 지하여야만 하는 것이 이번 생애 지상에서의 숙명이었던 것이다. 본디 시를 짓기보다는 그림을 그리고 싶어했다. 환쟁이로는 먹고 살기 어렵다는 어머니의 걱정에 차선으로 고른 것이 서울대 미학과였다. 하필이면 그 미학과가 미술대에서 문리대로 소속이 바뀌어 버린다. 노상 정치학을 비롯하여 인문학과 사회과학을 전공하는 친구들과 어울려 다녔다. 왕소금에 막소주를 들이키며 격정적으로 4.19와 5.16 이후의 시대를 논했다. 쿠데타로 정권을 접수한 박정희가 장기 집권을 획책하면서 학생들과의 긴장 수위는 나날이 높아졌다. 정보부 요원들이 본가에 들이닥쳐 김영일이 숨어 있는 곳을 대라며 부모님을 수차례 전기고문 했다. 끝내 아버지는 졸도하고 고혈압이 크게 터져 반병신이 되어 버린다. 도봉산 자락 아래 의암 손병희 선생의 묘소 근처에서 밝아오는 동쪽 하늘을 바라보며 영일은 굳게 맹세한다. 내 눈에 흙이 들어가기 전까지 반드시 박정희를 무너뜨리고 말리다! '김지하'가 탄생하는 순간이었다. 1970년, 그 유명한 '오적'을 발표한다. 장성부터 장관까지 다섯 무리의 공적을 지목하여 신랄하게 풍자한 담시였다. 판소리를 패러디하는 파격적인 패러다임 전환이 일품이었다. 가녀린 모더니즘의 서정시를 일거에 돌파하고 천둥번개 같은 남도의 토착적인 가락을 부여한 것이다. 문단과 세상을 한방에 뒤집어 엎었다. 하룻밤 새 지하는 일약 슈퍼스타가 된다. 1968년 미국에 지미 핸드릭스가 있었다면, 1970년 한국에는 김지하가 있었다. 실제로 노래 솜씨도 빼어났다. 랩 배틀, 훗날 가왕으로 등극하는 조용필과의 대결에서도 밤을 꼬박 새워 팽팽한 실력을 견줄만큼 남녘땅 뱃노래, 예인의 DNA를 타고 났던 것이다. 그해 연말에는 폭포수처럼 폭발하는 시집 '황토'까지 출간하며 단숨에 문화대통령, 시대의 아이돌로 부상한다. 전국의 대학가에서 지하의 시를 읽고 노래하는 문학의 밤이 들불처럼 퍼져 나갔다. 지하에 열광하는 팬덤이 확산되어 가는 영광의 세월이 지펴갈수록 정작 김지하는 고난과 수난의 시절에 들어가지 않을 수 없었다. 유신체제를 선포한 독재정권의 제1표적이 되었기 때문이다. 내란의 우두머리, 사형선고와 무기징역이 내려졌다. 지하의 독방 생활은 유난히도 가혹했다. 지하 한 사람을 가두기 위해 그의 감방 양쪽으로 스무 개 방을 모두 비워버렸다. 아래층과 윗층까지 비워서 통방 자체를 봉쇄해 버린 것이다. 텅텅 빈 절대적이고 절망적인 적막 속에서 사람 얼굴을 보기도 힘들었고, 인간의 목소리를 듣기도 어려웠다. 면회도 불가하여 누구도 만날 수 없었고, 가벼운 운동조차 허락되지 않았다. 늘 교도관 두 명을 배치하여 지하를 감시케 한 것으로도 모자라, 독방 위쪽에 설치된 카메라로 일거수일투족을 24시간 내내 지켜보았다. 온전한 정신으로 버티기가 어려워 괴로움에 발작하듯 몸부림이라도 칠라 하면 냉큼 달려와서, 전향서를 쓰라며 악마의 유혹을 건네었다. 독수골방의 면벽수행, 악으로 버티고 깡으로 견디어 내었던 세월이 자그마치 6여년, 2천일을 넘었다. 본디 약골에 심약한 사람이었다. 고질병인 폐결핵이 심해서 휴학을 거듭하며 대학도 7년 반이나 지나 졸업했을 정도이다. 식은땀을 줄줄 흘리고 해골처럼 마른 몸에 쿨룩쿨룩 기침을 하며 끊임없이 피 가래를 뱉어 내었다. 기흉을 의심할 정도로 가뿐 숨을 몰아쉬는 호흡 장애도 있었다. 수감 생활이 길어지면서 절로 마음 깊은 곳 구석구석에까지 곰팡이가 피어 갔다. 정신이 황폐해져 간 것이다. 군사독재의 독극물이 천재 시인의 두뇌를 야금야금 갉아먹었다. 1980년 12월 12일 마침내 출옥의 문이 열렸을 때, 이미 그는 섬맘증이라는 치명적인 정신분열 질환을 앓고 있었다. 천형과도 같은 신병, 영혼의 질병이 생긴 것이다. 박정희는 갔지만 전두환 치하였다. 감옥 밖이었지만 요주의 인물에 대한 감시가 그치지 않았다. 도주와 체포, 구금의 반복 속에서 PTSD, 외상 후 스트레스 장애, 트라우마가 심했다. 자라 보고 놀란 가슴 솥뚜껑 보고도 놀라는 법, 집에 전화가 걸려오거나 초인종만 울려도 심장이 벌렁벌렁 뛰었다. 아편처럼 깡소주를 달고 살았고, 정신병 약도 끊을 수가 없었다. 폐와 간과 위와 골이, 오장육부가 성하기 힘들었다. 고질병에 골병까지 삭신이 쑤시고 골수마저 아팠지만 아내와 자식이 있기에 스스로 목숨을 끊지도 못했다. 반면으로 그토록 처절하게 온 마음, 온 몸으로 시대를 앓았기에 범인들은 감히 범접할 수 없는 섬광 같은 깨달음으로 진입할 수도 있었다. 예수의 고난과 싯다르타의 고행에 못지 않은 고독의 천벌을 감내한 것이다. 김지하가 타는 목마름으로 민주주의를 갈망했던 세월은 실상 그리 길지 않았다. 5.18 소식을 감옥에서 접하고 밤새 잠을 이루지 못한 지하는 저항과 투쟁 일변도의 민주화 운동만으로는 새로운 세상을 열 수가 없다며 근원적인 작별 인사를 고했기 때문이다. 악전고투 끝에 생명 사상가로서 크고 깊이 회심한 것이다. 지하에서 영일로, 굳은 땅을 비집고 뚫고 나와 드넓은 하늘을 향해 새싹이 트고 기어이 꽃 한 송이를 피워내는 저 우주생명의 위대함과 거룩함을 갈파하기 시작한 것이다. 하지만 태초의 말씀을 전파하는 예언자의 일갈을 경청하는 귀가 좀체 모자랐다. 5.18 이후 운동권은 더욱 급진화된다. 민족해방과 계급해방을 외치는 목소리가 갈수록 드세져갔다. 1987년 민주화와 1989년 동서냉전 해체 이후에도 사정은 크게 달라지지 않았다. 1991년 드디어 사달이 난다. 다시 5월, 초개처럼 목숨을 던지는 운동권 청년들을 질타했다. 그 유명한 '죽음의 굿판' 사태이다. 조선일보에 투고한 원래 글의 제목은 '젊은 벗들, 역사에서 무엇을 배우는가'였다. 혁명보다 소중한 것이 생명이다. 생명을 버리는 혁명은 어불설성이다. 어리석기 짝이 없는 분신정국의 자살 행렬을 멈추라는 지하의 뼈저린 외침에 운동권들은 변절자라며 낙인을 찍고 전향이라고 손가락질했다. 지하는 영원히 저항시인일 것을 요구한 것이다. 민족문학작가회의 또한 그를 제명한다. 충격이었다. 머리에 한가득 침을 맞아야 할 만큼 고통스러운 세월이었다. 돌아보면 김지하는 독재정권과는 20여년 불화했지만, 운동권과는 세상을 등지기 전까지 30년 이상 갈등하며 끝끝내 화해에 이르지 못했다. 말년에는 박근혜 후보를 지지하며 산업화 세력과의 화해를 도모하고 여성이 이끌어가는 생명문명으로의 진일보에 기대를 걸면서 돌이킬 수 없는 다리를 건너고 말았다. 이 두 번의 결정적인 사건으로 지하는 '빠'보다는 '까'를 몰고 다니는 희대의 빌런이 되고 만다. 그러함에도 나는 김지하만이 22세기에도 읽힐만한 유일한 20세기의 한국 사상가로 꼽는데 주저함이 없다. 그의 독보적이고 독창적인 득의 또한 1970년대의 시집들이 아니라, 1987년 이후에 쓰여진 저작들이라고 확신한다. 특히 1989년에 발표한 '한살림 선언'이 각별하다. 그 이전 운동권에서 산출한 숱한 텍스트들은 죄다 아류에 불과하다. NL과 PD를 가릴 것 없이 몽땅 주석서와 강해서, 짝퉁일 뿐이다. 계급해방을 주장한 PD는 마르크스를 읽으면 된다. 민족해방을 역설한 NL은 마오쩌둥을 읽으면 그만이다. PD는 마르크스의 아류인 레닌의 소련을 섬겼고, NL은 마오쩌둥의 아류인 김일성의 북조선을 북극성으로 삼았다. 오직 김지하만이 북조선도 아니요 소련도 아닌, 우리의 터전인 남한의 뿌리로 깊이 파고들어 도저한 지하수맥을 만나 미래의 대안을 구한 것이다. 황해 건너 중국의 유학도 아니요, 인도양과 태평양 너머 서학도 아닌, 1860년 동학의 탄생으로 되돌아가 이 땅의 창조적인 원전과 정전을 홀로 창작해낸 것이다. 그래서 어용지식인과 재래식 사상가들이 '민주주의'라는 무한 돌림노래를 신물이 나도록 반복하고 있는 87년 이후에도 독야청청 독보적인 생명사상을 개척해갈 수 있었다. 부디 혁명이 아니라 신명을, 제발 문명이 아니라 생명을- 신들린 듯이, 신 내린 듯이, 타는 목마름으로 피를 토하듯 노래했다. 지하의 가장 큰 사상적 혁신은 동학 중에서도 전봉준이 아니라 최시형, 해월 선생님을 드높인 것이다. 녹두장군의 무모한 무장투쟁으로 호남 들판은 피로 물들고 말았다. 죽창가를 부르며 팔뚝질 하면서 짱돌을 들고 화염병을 던지는 항쟁이 아니라 모심의 정신과 살림의 정성으로 등불을 밝히는 해월신사를 되살려 내면서 훗날 촛불과 응원봉의 여명을 일찍이 예감한 것이다. 개화우파 산업화세력과 개화좌파 민주화세력을 아우르고 넘어서는 좌우 포월의 개벽파를 호출해낸 것이다. 진작에 유효 기간을 다해버린 87년체제 너머의 상상력을 길어 올리기 위해서도 김지하가 토해낸 1987년 이후의 텍스트들을 깊이 천착해야 하는 까닭이다. 전 세계의 미래세대를 감화시키고 있는 K-문화의 열풍을 받아 안아 K-문명으로 승화시키기 위한 씨앗들을 도처에 묵묵히 흩뿌려 놓았기 때문이다. 실제로 김지하야말로 한류의 원조였다고도 할 수 있다. 수갑을 차고 푸르른 수의를 입고 있는 사형수 김지하의 옆모습이 온 세상을 파르르 전율케 하는 시절이 있었다. 혁명가 체 게바라와 예술가 밥 딜런를 합해 둔 것과도 같은 광채의 아우라를 뿜어냈다. CHE와 BOB을 능가하는 JIHA가 된 것이다. 그 남조선의 지하가 글로벌 아이돌로 비상하는 데에는 이웃나라 일본의 역할이 다대했다. 지하 다방의 투박한 그 '地下'에 '芝河'라는 우아한 한자 조어를 붙여준 곳이 바로 일본이었다. 1971년 12월, 김지하의 주요 작품을 번역한 '긴 어둠의 끝'을 중앙공론사에서 출간함으로써 지하의 행보가 전 세계에 알려지게 된다. 오에 겐자부로는 자신이 아니라 지하야말로 노벨문학상을 받아야 한다고 겸양했다. 유럽에서는 사르트르와 마르쿠제가, 미국에서는 하워드 진과 노암 촘스키, 수잔 손택 등 당대를 주름잡았던 기라성 같은 지성인들이 김지하를 석방하라며 박정희 정권을 압박했다. 地下가 芝河를 거쳐 'JIHA'가 되어간 것이다. 결국 노벨문학상의 대안이라고도 일컬어졌던 아시아-아프리카 작가회의가 수여하는 로터스상을 받기에 이른다. 동서냉전과 좌우투쟁 사이 제3의 길, 제3세계의 혼불로 우뚝했던 것이다. 2. ICON: 한살림과 홀어스 산업화 다음이 민주화가 다가 아니었다. 김대중은 정보화를 내세웠다. 김우중은 세계화를 주창했다. 김지하는 생명화를 새로운 테제로 내걸었다. 돌아보면 출옥 이후 1981년 로터스상 수상 연설문에서부터 민주가 아니라 생명을 표방했다. 군사독재라는 일국적 차원이 아니라, 생명의 위기라는 전 지구적 차원에서 당대를 조망했다. 산업문명의 쌍생아인 자본주의와 공산주의를 동시에 넘어서는 문명의 대전환을 요청한 것이다. 자유주의나 사회주의 같은 이데올로기의 한계도 설파했다. 생명의 세계관에 기초한 온생명의 온톨로지를 탐구한 것이다. 1985년 지하는 땅끝 마을, 해남으로 간다. 새로운 것은 늘 끝에서 변방에서 엣지에서 발아하기 때문이다. 노동운동이나 민족운동과는 전혀 다른 생명운동의 기항지로 삼은 것이다. 원주에서 싹튼 생명사상과 해남에서 일군 생명운동이 통합되어 산출된 문건이 바로 1989년 '한살림선언'이다. 베를린 장벽이 무너진 바로 그 해이다. 남북과 좌우와 동서를 망라한 하나의 거대하고 거룩한 한살림을 모색했다. 1991년 소련이 해체되자 운동권 또한 새로운 방향을 모색하지 않을 수가 없었다. 1989년 경제정의실천연합(경실련)이 발족되었고, 1994년 참여연대가 발기하였다. 동구의 몰락 속에서 서구의 NGO 형태의 시민운동을 차용한 것이다. 김지하는 재차 신좌파들의 유러피안 드림, 구미 편향을 사절했다. 커녕 오히려 거대한 뿌리에 접속하여 더욱 더 한국적인 것, 아주 더 오래된 토착적인 것으로 더 멀리 돌아간다. 율려와 풍류와 신시와 화백이라는 화두를 꺼내어 들고 나온 것이다. 1996년에는 신풍류회의를 발족한다. 1998년에는 율려학회를 조직한다. 한국의 고유한 생명사상을 정립하고 독자적인 생명문화를 창조하고자 분투한 것이다. 21세기 새 천년을 맞이해서는 세계와의 소통을 도모했다. 경기도지사 손학규의 도움으로 세계생명문화포럼을 개최한다. 2003년에 시작해서 2006년까지 네 차례 진행되었다. 다보스에서 진행되는 세계경제포럼이나 제3세계에서 열리는 세계사회포럼과도 일선을 그었다. 좌파와 우파가 아닌 개벽파들의 생명문명을 탐구하는 첫번째 회합을 한국에서 조직해낸 것이다. 때는 한참 노무현 정권이었으니 김지하는 신주류가 되어가는 민주화 세력과는 또 다른 차원에서 신문명 모색을 지속했던 셈이다. 이 포럼을 잘 운영하기 위해 '생명과 평화의 길'이라는 단체도 만들었다. 훗날 이효리와 황희찬의 타투로 유명해진 '생명평화무늬'도 이 운동의 여정 속에서 탄생했던 것이다. 노동운동가에서 전향한 김문수가 도지사가 되면서 세계생명문화포럼에 대한 지원이 끊어진다. 안타까운 일이다. 지속되었더라면 전지구적 생명의 위기를 실감했던 코로나 팬데믹을 전후하여 세계경제포럼에 못지 않은 상징성을 확보할 수 있었을지 모른다. 다보스 포럼을 능가하는 발언력과 발신력을 대한민국 K가 보유할 수도 있었다. 지하의 생명사상 탐구가 더욱 미더운 것은 녹색당 계열의 생태 진영과도 결을 달리했다는 점이다. 군계일학, 한쪽으로는 맹렬하게 디지털로 나아갔고 다른 한 편으로는 우주를 향해 진화해갔다. '방콕의 네트워크', '디지털 생태학', '우주생명학' 등을 연달아 집필하며 에콜로지와 테크놀로지가 합류하는 미래를 예감하고, 우주 저 멀리까지 생각과 생명이 확산되는 토착적인 SF적 사유를 개진해 나간 것이다. 디지털문명과 우주시대의 개창 속에서 새로운 종교적 각성까지도 내다보았다. 신의 진화와 마음의 진화와 우주의 진화가 합류하는 새로운 우주종교의 탄생을 예지한 것이다. 생물의 자연적 진화와 인간의 자각적 진화에 활물의 자율적 진화가 하나가 되어가는 우주적 차원변화를 '후천개벽'의 개념으로 설파한 것이다. 인간은 신령스러운 우주생명의 유일한 자의식이다. 우주적 대해탈을 추동하는 윤리적 주체인 것이다. 김지하로 말미암아 19세기의 동학과 20세기의 한살림이 글로벌 K의 우주문명으로 도약할 수 있는 발판을 마련한 것이다. 동시대 김지하처럼 사고한 사람은 미국의 사업가 스페이스X의 일론 머스크였다. 그런데도 여전히 지하를 추모하고 기념하는 자리는 과거완료형이다. 49재가 되는 2022년 6월 25일, 수운회관에서 열리는 행사에 가보았다. 그 해 가을 한국학중앙연구원에서 열린 학술회의도 참관했다. 가장 뒷자리에 우두커니 서서 발표와 토론을 지긋이 경청했다. 심히 아쉬웠고 깊이 안타까웠다. 여전히 문사철, 시서화에 그친다. 도무지 STEM, 과학과 기술, 공학과 수학으로 김지하를 과감하게 연결해내지 못한다. 한중연의 전신이 바로 정신문화연구원이다. 박정희가 과학기술원과 함께 만든 곳이다. 과학기술과 정신문화의 쌍두마차로 대한민국의 미래를 설계했던 것이다. 공교롭게도 김대중은 IT 산업의 메카를 정신문화연구원 근방의 판교에 세웠다. 그 판교의 테크노벨리에서 출발하여 한중연까지 두어 시간 남짓 터벅터벅 걸어 갔다. 서로 소 닭 보듯 멀찍한 한중연과 테크노밸리를 연결해야 한국의 테크기업들도 실리콘밸리와 같은 '사상'을 발신하고 발산할 수 있다. 그 한국형 테크-사상의 원형으로서 김지하 만한 인물이 없다고 여긴다. 어떻게 판교의 테크노밸리에서 일하는 프로그래머와 엔지니어와 창업가와 투자자들에게 지하의 우주생명사상을 접속시킬 것인가, 나의 오랜 고민이자 화두이다. 사례가 없지 않다. 한국에 김지하가 있었다면, 미국에는 스튜어트 브랜드(Stewart Brand)가 있었다. 지하는 1941년생이고, 브랜드는 1938년생이다. 지하는 '요기싸르'가 되고 싶어 했다. 요기는 인도의 수행자요, 싸르는 혁명 위원회 코민싸르에서 따 온 말이다. 요기싸르란 안으로는 내면의 평화를 추구하면서, 밖으로는 사회적 변혁을 추진하는 것이다. 정신의 개벽과 물질의 개벽으로 천지를 개벽하는 일이다. 브랜드 또한 다르지 않았다. 다만 지하가 인간의 사회적 성화에 그쳤다면, 브랜드는 인간의 기술적 성화로까지 나아갈 수 있었다. 지하의 땅 끝 마을이 한반도 최남단 해남이었다면, 미국 중서부에서 태어난 브랜드의 땅 끝 마을은 웨스트코스트, 바로 캘리포니아의 실리콘밸리였기 때문이다. 태평양 사이 두 나라의 풍토의 차이와 산업 발전의 시차가 두 사람의 인생을 결정적으로 갈라놓았다. 브랜드는 스탠퍼드 대학에서 생물학을 전공한다. 지하가 민주화운동의 아이콘이었던 것처럼, 브랜드 역시도 68혁명으로 상징되는 미국의 저항문화에 흠뻑 취한 인물이었다. 히피들과 어울리며 생태운동에 깊이 천착했고 아메리카 원주민의 토착문화는 물론 아시아의 정신세계에도 깊은 매력을 느꼈다. 지하가 지독한 수감생활로 섬망을 앓으며 섬광 같은 깨달음을 얻었다면, 브랜드는 LSD 파티를 오가며 평상시와는 다른 비범한 정신세계를 경험했다. 환각을 통하여 시각을 넘어서는 차원의 신세계에 입문함으로써 마인드 테크놀로지를 탐구한 것이다. 지하와 브랜드의 인생을 갈랐던 또 하나의 결정적인 차이에는 컴퓨터라는 도구도 있었다. 컴퓨터의 유무로 말미암아 지하는 '한살림'이라는 일국적 비전에 그쳤고, 브랜드는 'WHOLE EARTH'라는 글로벌 브랜딩을 론칭할 수 있었다. 브랜드는 냉전시대 중앙집권적 관료주의의 상징이었던 컴퓨터를 히피들의 반문화 커뮤니티에 접속시킨다. 정치적 급진화로 치닫는 신좌파(new left)와는 달리 디지털 커뮤니티(new communalist)의 창조로 진화해간 것이다. 그래서 창간한 잡지가 바로 WHOLE EARTH CATALOG이다. 1968년에 시작되었다. 달에서 관찰한 지구돋이(Earthrise)를 표지로 삼았다. 온지구의 한살림을 천착하는 인류 의식의 수직적 진화를 상징했던 것이다. 컴퓨터라는 신기술에 대한 예찬에서 보듯이 도구/기계에 대한 생각도 결을 달리했다. 사물 또한 생물처럼 진화하면서 지구의 행보에 결정적인 영향을 미친다고 여긴다. 'Access to tools'를 슬로건으로 인간과 기술의 공진화를 강조한 것이다. 소프트웨어를 인간 의식의 확장과 심화의 도구로 여겼고, 디지털을 통한 가상의 커뮤니티 창조를 탐구했다. 1970년대에는 CoEvolution을 창간했고, 1980년대에는 WELL(Whole Earth Lectronic Link) 창설을 통해 온라인 공동체와 가상의 정체성을 실험했다. 그리하여 1989년 월드와이드웹(World Wide Web)의 출발과 함께 분출하는 IT 혁명과 디지털문명의 출발에 발맞추어 갈 수 있었다. 1993년에는 '와이어드(WIRED)'도 창간한다. 1991년 한국에서 창간된 '녹색평론'과 견주노라면 현저한 차이가 도드라진다. 기후격변과 기술폭발을 아울러 신문명을 탐사하는 WIRED와는 달리 한국의 생태잡지는 기술폭발과는 일절 담을 치고 말았기 때문이다. 베를린 장벽으로 상징되는 이념의 벽이 무너지던 순간에 에콜로지와 테크놀로지 사이에 만리장성을 쌓은 것이다. 오로지 김지하만이 21세기의 약동에 발맞추어 디지털을 직시했다. 김지하가 생명의 위기가 임박했다고 설파한 2009년 브랜드는 'WHOLE EARTH Discipline'를 출간하고 전 지구적 차원에서의 살림살이 방안을 제시한다. 인공지능(AI)의 부상과 기후변화 속에서 핵융합 발전과 생명공학으로 탈멸종 프로젝트를 대안으로 표방한 것이다. 툰베리로 상징되는 유럽의 10대들처럼 멸종저항 운동의 가두시위를 하는 대신에, 생명공학으로 멸종된 종들을 되살려 되는 바이오 엔지니어링에 몰두한 것이다. 그리고 1996년 LONG NOW FOUNDATION도 창립한다. 행성적 관점에서 한 달과 일년의 단기적 판단이 아니라, 천년과 만년에 이르는 장기적 사유를 강조한 것이다. 1만년 단위의 시계도 설계하여 네바다 산 속에 설치한다. 백년년에 한 번 종소리를 내고, 천년에 한번은 뻐꾸기 알람 소리를 낸다. 백년을 한 시간처럼, 천년을 한 달처럼. 마치 1만년 전 농업문명이 시작되었듯이, 1만년 후 신문명을 상상하면서 기나긴 현재를 숙고하자는 취지이다. 그래서 2026년 또한 “02026”으로 표기한다. 이처럼 비범한 브랜드의 사상적 영향력은 실리콘밸리에 두루 깊이 아로새겨져 있다. Whole Earth Catalog를 계승한 '와이어드'는 지금도 테크놀로지에 문화와 사회와 정치를 변혁시키는 사상의 힘을 부착하는 역할을 하고 있다. 철학적 관점을 제기하고 논쟁을 주도함으로써 디지털 문명의 서사를 만들어내고 있다. 실리콘밸리의 자아 성찰 거울이자 미국 및 세계와 소통하는 창구라고도 할 수 있다. IT혁명에서 AI혁명까지 30년이 넘도록 실리콘밸리의 자화상을 그려온 것이다. 브랜드의 영향을 받아 창업한 기업들도 숱하게 많다. 으뜸은 스티브 잡스이다. 그의 그 유명한 'Stay Hungry, Stay Fooish' 정신이 바로 WEC에서 따온 말이다. 개인의 해방이라는 애플의 I 시리즈의 뿌리에 68정신의 기술적 진화를 표방한 WEC가 있었다. Access to Tools 정신 또한 애플 제품 고유의 사용자 중심 디자인으로 이어졌다. 구글 또한 WEC와 밀접하다. 브랜드의 '정보 해방'(Information wants to be free) 정신과 WEC의 정보 접근 철학이 고스란히 만인과 만물과 만사의 백과사전이자 검색엔진으로서 구글을 추동했던 것이다. 카탈로그가 표방했던 지식과 정보의 민주화가 고스란히 디지털로 옮아가 구글을 낳은 것이다. 아마존의 제프 베이조스 또한 WEC로부터 영감을 받았다. 카탈로그 형식의 책과 사물에 대한 리뷰가 지구상 가장 큰 온라인 서점의 콘셉트로 진화한 것이다. 온라인 상거래의 사용자 중심 네트워크 모델 또한 WEC에서 뻗어 나온 발상이다. 세계 최고의 친환경기업이라 할 수 있는 파타고니아의 이본 쉬나드도 WEC의 영향을 받았다. 브랜드의 생태적인 전체론적 시스템 사고가 Earth First라는 파타고니아의 비전을 촉발한 것이다. 구글의 'Don't be evil'이나 파타고니아의 'Don't buy this jacket' 같은 슬로건 역시도 브랜드의 영향이라고 해도 지나치지 않을 것이다. 브랜드의 1만 년 단위 장기적 사유 관점은 초장기주의자이자 초가속주의자인 일론 머스크의 모든 비즈니스에도 막대한 영향을 미쳤다. 브랜드의 생각이 테크 산업의 생산을 낳았고, 브랜드의 사상이 실리콘밸리의 사업으로 승화된 것이다. 그래서 샌프란시스코는 원주와 해남과는 달리 미래산업을 주도해갈 뿐만이 아니라 미래의 사상과 담론도 이끌어가고 있는 것이다. 대학과 언론 등 산업문명의 재래식 기관들이 아니라 테크기업의 CEO들이 디지털 문명을 선도하는 제자백가 역할을 하는 것에도 스튜어트 브랜드와 WEC가 있었다고 할 것이다. 다시 한국의 판교를 돌아본다. 넥슨과 앤씨소프트가 있고, 네이버와 카카오도 있다. 삼성과 SK, 현대와 관련된 조직도 여럿이다. 그러나 판교의 테크노밸리에서는 '이야기'가 들리지 않는다. 서사가 없다. 인류와 미래와 우주에 대한 위대한 이야기를 발신하는 사람들이 없다. 사상이 부재하기 때문이다. 철학이 결락되어 있기 때문이다. 그래서 알렉스 카프는 판교가 아니라 성수동에 팔런티어의 팝업 스토어를 열었다. 그리고 그 누구도 만나지 않고 대화도 나누지 않았다. 다보스포럼에서 블랙록의 래리 핑크와 대담하는 것과는 딴판인 것이다. 말이 통하는 사람을 찾지 못한 것이리라. 젠슨 황 역시도 깐부들과 치맥 파티를 즐겼을 뿐이다. 메시지는 잰슨 황이 발신하고 한국의 CEO들은 건배만 할 뿐이다. 엔비디아의 CEO가 이야기하는 미래에 말과 글로써, 생각으로 사상으로 참여하지를 못하는 것이다. 그래서는 여전히 주가 아니라 객, 아류에 불과한 것이다. 남품업체, 하청기업에 그친다. 이야기를 발신할 수 있어야, 한다. 꿈을 팔 수 있어야 한다. 그래야 저평가된 주식 시장도 대폭발 할 것이다. 상법 개정만으로는 족하지 못하다. 상상의 나래를 활짝 펼쳐야 한다. 한국의 서학개미들이 실리콘밸리의 빅테크 기업들에 열광하는 것처럼, 1990년대 이후 태어난 아시아의 미래세대들이 경험할 탈노동사회와 투자사회의 대안으로 한국의 빅테크들을 주목하도록 고유한 네이티브 내러티브를 주조해가야 한다. 실리콘밸리가 파는 것 또한 단순히 기술만이 아니기 때문이다. 그 기술이 구현하는 미래의 사상과 철학을 설파하는 것이다. 머스크도 하사비스도 카프도, 디지털 문명의 여명기에 등장한 춘추전국의 제자백가들인 것이다. 새로운 나라를 일으키고, 새로운 문명을 건설하겠노라 담론을 팔고 무리를 지으며 팬덤을 만들어 가고 있다. 삼성도 SK도 LG도 네이버도 '최고철학책임자'(CPO)가 필요하다. 반면 한국의 한살림은 여전히 생협에 그친다. 기계와 생명을 물과 기름처럼 나누었던 1989년의 선언으로부터 그다지 나아가지 못한 것이다. 조합원들조차 김지하를 알지 못하는 경우도 적지 않다. 어떻게 지지부지한 한살림과 이야기가 부재한 판교를 연결해낼 것인가. 한국학중앙연구원과 테크노밸리를 어떻게 접속시킬 것인가. 그래야 한살림도 K의 물결에 합류할 수 있을 것이다. 물들어 올 때 노를 저어야 한다. K-팝, K-뷰티 등 한국의 의식주 모두가 각광을 받고 있는 이 천금 같은 기회에 올라타서 전 지구적 살림살이, K-살림의 방향을 제시할 수 있어야 하는 것이다. 밥이 하늘이라고 했다. 만사지식일완(萬事知食一碗), 밥이 곧 문명이자 생명이었다. 유독 익히고 삭히고 묵히는 한국의 밥과 장, 그 기나긴 현재(long now)의 음식 철학과 발효의 미학을 K-팝을 잇는 K-밥으로, 'BOB'으로 승화시키는 것이다. 나는 그것이야말로 죽어서도 '김지하'여야만 하는 김영일의 숙원을 풀어내는 해원상생의 첩경이라고 생각한다. 우리에게도 WEC가, 'WIRED'가 필요하다. 3. IU: 우주와 민주 산업문명은 찢어진 문명이었다. 에콜로지와 테크놀로지의 불화가 지구의 신진대사를 망가뜨렸다. 불타는 기후 격변을 촉발시켜 1만 2천년 홀로세를 종식시킨 것이다. 사피엔스의 전성기였던 충적세가 극적으로 마감되고 있다. 이제 인류는 전혀 다른 기후대에서 새로운 살림살이를 도모해야 한다. 농업문명으로의 퇴각이 대안이 될 수 없다는 말이다. 하늘이 무너져도 솟아날 구멍이 있는 법, 공교롭게도 한살림선언이 발표된 1989년 등장한 WWW가 기계와 생명 사이 그물망을 만들어내고 있다. 정보의 알고리듬으로 생명의 오가니즘과 기계의 매커니즘이 합류하게 된 것이다. 마침내 지질권과 생태권과 생물권과 인간권을 기술권이 연결하는 한살림의 테크놀로지를 디지털 문명이 선사하고 있는 것이다. 이로써 물리학적 행성에 그쳤던 지구(EARTH)가 자의식을 장착한 가이아(GAIA)로 진화한 것이다. 천주와 군주와 민주를 지나 마침내 우주에 이르게 되었다. 가이아의 7할은 물이다. 바다가 지구의 70%를 점한다. 그래서 지구가 아니라 수구, 플래닛아쿠아라고도 한다. 그 드넓은 바다의 대장은 고래이다. 그 범고래를 아쿠아리움에서 풀어주는 것만으로는 충분하지 못하다. 그들에게 디지털 장비를 부착시킬 수가 있다. 사람들이 페이스북으로 소통하듯이, '와일드북'을 붙여주는 것이다. 그러면 바다라는 '월드 와일드 웹'으로 돌아간 이후의 삶도 트래킹할 수 있다. 인공지능 알고리즘으로 수중 녹음을 분석하여 고래의 소리를 분류하고 그 의미를 헤아릴 수도 있다. 울산 바위의 암각화에 새겨진 그 오래 전 고래들의 암호 코드를 해독할 수 있게 된 것이다. 덕분에 아기 고래의 미세한 소리도 이해할 수 있다. 어미 고래가 롯데타워보다도 4배나 더 깊이까지 잠수하다는 사실도 알아낼 수 있다. 고래의 내비게이션을 통해서 해류의 방향과 속도를 파악할 수도 있다. 바다의 온도와 산도와 염도부터 플랑크톤과 연어의 움직임까지도 알 수 있다. 그리고 지하 깊은 곳에서 물 속으로 퍼지는 미묘한 지진의 진동까지도 모니터링할 수도 있다. 고래의 생태 정보는 물론이요 5대양의 운동을, 플래닛 아쿠아의 심장 박동을 파악할 수 있게 된 것이다. 수구의 3할, 땅에서 살아가는 동물들에게도 디지털 디바이스를 부착하고 있다. 염소와 코뿔소, 거북이와 코끼리 등 6대주에 퍼져 있는 다종다양한 동물들의 살림살이에 해시태그를 달아주는 것이다. 그들의 이동을 추적하다 보면 저절로 툰드라와 타이가, 열대우림부터 사막과 초원의 상태까지 정보로 변환하여 데이터로 파악할 수 있게 된다. 육지와 해양을 가르지 않고 하늘을 날아다니는 새들과 곤충들에게도 바이오 칩을 삽입하고 있다. 농업 생산에 지대한 역할을 하는 꿀벌에도 센서를 달아 위치와 온도, 습도와 빛의 세기를 측정할 수도 있다. 꿀벌의 추적기가 벌통에 드나들거나 꽃을 찾아 원정을 오갈 때마다 그들의 움직임을 스캔해 주는 것이다. 이로써 동식물은 물론이요 대지와 대양과 대기의 운동도 실시간으로 파악하는 스마트 지구, 디지털 홀어스의 정보 흐름을 가시화할 수 있게 된다. 살아 있는 지구, 숨 쉬고 있는 수구, 가이아의 심호흡을 디지털 트윈의 딥데이터로써 대면할 수 있게 되는 것이다. 시각만도 아니다. 청각 혁명도 일어나고 있다. 디지털은 그간 인간이 보지 못하던 것을 보여줄 수 있을 뿐 아니라, 듣지 못하던 목소리도 들려주고 있다. 사람의 귀가 들을 수 있는 주파수 밖의 소리들에게도 '목소리'를 부여하고 있는 것이다. 예컨대 코끼리들도 그들 만의 주파수를 사용하여 원거리에서도 텔레파시를 주고받는다. 산호초에서는 다양한 생물들이 음향적으로 정보를 공유한다. 물고기들은 그 소리를 감지하여 건강한 산호초를 분간해 낼 수 있다. 즉 자연은 애초부터 침묵하고 있지 않았다. 그들의 언어로 태초의 말씀을 전파하고 있었다. 즉 자연은 늘 노래한다. 합창곡과 교향곡이 멈추지 않고 연주된다. 다만 인간이 듣지 못했을 뿐이다. 디지털과 알고리즘, AI기술의 폭발적 진화로 말미암아 비로소 우리는 동물과 식물의 의사소통을 알아들을 수 있는 신시대로 진입하고 있는 것이다. 외국어 넘어 외계어의 암호를 해독한 결과물은 참으로 경이롭다. 옥수수와 토마토도 고유의 초음파를 발신하고 있었다. 곤충들은 오래전부터 알아들었다. 우리가 그와 같은 곤충들의 귀를 디지털로 구현하게 되면, 건강한 식물, 탈수된 식물, 상처 입은 식물들의 목소리를 들을 수 있게 된다. 마침내 선사 시대의 원주민들이 자연과도 소통할 수 있었다는 머나먼 신화 속 이야기처럼 테크놀로지를 통하여 인간이 동물은 물론이고 식물과도 소통할 수 있게 되는 것이다. 판도라 행성의 아바타처럼 정녕 새로운 '발견의 시대'(Deep Discovery)가 열리고 있다고 해도 모자람이 없을 정도이다. 가상현실(VR)과 증강현실(AR)을 활용하면 시청각을 넘어 촉각과 후각, 심지어 미각까지 해킹할 수 있다. 증강현실을 통해 숲 속에서 살아가는 동물처럼 환경을 경험할 수도 있다. 증강된 숲에서 벌처럼 새처럼 날아다닐 수도 있다. 날개를 퍼덕이며 나는 느낌을 감각할 수 있는 것이다. 즉 인간이 다른 동물의 지각적 존재 방식에 완전히 몰입할 수 있게 된다. 역지사지의 범위가 타인을 넘어서 다른 종으로까지 확장되는 것이다. 인간의 뇌는 현실 세계의 경험을 저장하고 접근하는 것과 동일한 방식으로 VR과 AR의 메모리를 저장한다. 즉 뇌는 가상 현실이 실제이며 실제로 그 안에 존재한다고 믿는 것이다. 이는 책을 읽는 것이나 강의를 듣는 것이나 영화를 보는 것과는 차원이 다른 경험을 선사한다. 신체적 몰입감이 감정적 친밀감으로 승화한다. 가상의 영상이 명상과 영성의 단계로 도약하는 것이다. 공감의 대상이 전면적으로 확대되는 것이다. 오감을 자극하여 육감을 일깨우고 만감이 교차하도록 한다. 이토록 굉장한 세계, 인간과 만물의 공속감을 배양하게 되는 것이다. 지구의 저속노화를 촉발할 수 있는 기술적 잠재력이 무궁무진한 것이다. 로봇 자체를 생물화할 수도 있다. 인간을 닮은 로봇, 휴머노이드로 상상력이 그치지 않는다. 동식물의 다종다양함만큼이나 바이오봇의 형태와 기능 또한 다채로울 수가 있다. 가령 지표면을 가득 메우고 있는 이끼봇도 가능하다. 생태와 환경의 모니터링 장치로 요긴하다. 위험한 화학물질과 폭발물을 탐지하는 데도 사용될 수 있다. 감지 장치로서의 수명이 다하면 자연스럽게 썩어서 분해되게 만들 수도 있다. 지하에는 균사체, 버섯들의 네트워크가 장대하다. 곰팡이라고도 불리는 엄청난 연결망이 땅 아래에 넓고 깊이 퍼져 있다. 지구 상에서 가장 오래되고 가장 큰 생명계라고도 할 수 있다. 여기에 테크놀로지를 합성시켜 버섯봇을 만들 수도 있다. 버섯과 로봇과 컴퓨터, 즉 오가니즘과 매커니즘과 알고리즘이 합성된 유기체적 제품을, 컴퓨팅하는 생물을 창조할 수 있는 것이다. 결국 컴퓨팅이라는 테크놀로지는 지구의 모든 곳과 모든 것에 녹아들어가게 될 것이다. 이 물리적 세계와 생물적 생태계에 계산기계가 삽입되어 감으로써 '보이지 않는 손'이 되어가는 것이다. 보이지 않는 신이라고 해도 좋다. 가장 궁극의 기술은 결국 마술처럼 사라지는 것이다. 인터페이스가 없어지는 것이다. 버튼도 없어지고, 마우스도 사라지고, 마이크도 필요 없으며, 터치 스크린도 지워진다. 문명과 생명의 모순이 해갈되고, 자연과 자유의 갈등이 해결되며, DNA와 DATA가 합류하는 I=U의 신천지가 펼쳐지는 것이다. 내 마음이 네 마음, 온마음이 한마음. 도시와 숲의 차이가 없어지고, 자동차와 구름의 차이가 사라진다. 사피엔스의 아주 먼 조상인 박테리아가 또 다른 박테리아를 인수 합병하여 상호 이익이 되도록 협력하는 방법을 배워 지구 상의 생명 현상을 창발했던 것처럼, 앞으로는 바이오와 디지털 사이의 M&A가 폭발적으로 전개되어 우주를 향해 확산되어 갈 것이다. 생명의 코드를 기계에 삽입하고, 컴퓨터의 알고리즘을 만물에 주입함으로써 모든 사물이 '활물'이 되는 새로운 창세기를 연출하게 되는 것이다. 그리하여 사람과 생물과 활물의 혼합과 조합은 더 이상 SF의 판타지가 아니게 된다. 나와 남의 구분이, 너와 나의 차별이 점차 흐릿해진다. 우리는 모두 졸졸졸 물처럼 흐르고 또 흐르는 스트리밍 거버넌스의 노드일 뿐이다. 2019년 '개벽파 선언'이라는 책을 내었다. 1919년 3.1 독립선언 100주년을 기념하고 싶었다. 또 1989년 한살림선언 30주년을 계승한다는 뜻도 있었다. 김지하의 그 '타는 목마름'을, 해갈되지 못한 갈증을 이어가고 싶었다. 개벽학당이라는 무허가 학교도 열었다. 동학부터 한살림까지 한국의 사상사를 곱씹어보는 한편으로, 구글과 MS 등 빅테크의 관계자들과 생명공학을 전공하는 분들을 모셔와서 강연을 듣기도 하였다. 그 '벽청들', 개벽하는 청년들과 함께 쿤밍에서 열리는 생명다양성 국제협약 회의에서 근사한 포퍼먼스를 열어보려고도 했다. 동아시아의 10대와 20대들이, 개벽의 딸과 아들들이 쿤밍의 공원에 모여 생명평화무늬를 연출하면 드론으로 촬영하여 세계 만방으로 발신하고 싶었다. '해월상'도 수여하려고 했다. 다이너마이트를 발명한 노벨상이 아니라 디지털-생명문명의 아이콘들에게 시상을 하려고 한 것이다. 지하가 되살려낸 해월 최시형의 '해월'이라는 호가 절묘했다. 바다(海)와 달(月)의 합성이다. 지구가 생명의 행성인 것은 물이 있기 때문이다. 그 물의 태반은 바다이니, 바다에 파도가 치는 것은 또 달과의 인력 때문이다. 도래하는 우주생명문명의 메타포로서 이보다 더 어울리는 브랜드는 없다고 여겼던 것이다. 그 해월상을 생각과 생활과 생산으로 나누고, 각각 프란치스코 교황과 툰베리와 머스크에게 주려고 했다. 노벨상보다 상금이 조금 더 많도록 20억을 책정했다. 교황과 머스크가 상금을 반려하면, 그 40억으로 다음해의 행사를 준비하면 되겠다는 짱구를 굴렸다. 한편으로는 지구법 공부도 열심히 했다. 산과 강에도 법인 자격을 부여하기 시작한 에콰도르와 뉴질랜드 등의 생태헌법을 연구한 것이다. 그러나 김지하가 경고한 대로 괴질과 역병, 코로나 팬데믹이 확산되어 가면서 생명다양성 국제협약(CBD) 회의도 무기한 연기되고 말았다. 과연 생태헌법의 개정과 국제조약의 준수로 이 파상적인 기후 격변에 대처할 수 있을 것인가, 근본적인 의문과 회의가 일었다. 다시금 타는 목마름이 일었다. 궁리 끝에 테크 창업가들을 찾아 다녔다. 기술개발로 기후변화에 대응해가는 한국의 창업가들을 물색하고 다녔다. 그들을 만나 나눈 이야기를 '어스테크'라는 책으로 엮어 내기도 하였다. 그러나 중과부적이었다. 몇몇 창업가들의 분골쇄신으로도 충분치 못했던 것이다. 글로벌 거버넌스 자체가 바뀌지 않고서는 유효한 대안이 될 수가 없었다. UN은 무력했다. 2015년 파리기후협약을 누구도 기억하지 않는다. 어느 나라도 제대로 지키지 않는다. 기후변화 자체를 불신하는 트럼프 대통령은 노골적으로 UN을 무력화시키고 있다. 지나치게 거칠어서 황당한 마음도 없지 않으나, 1945년에 만들어진 UN이 더 이상 디지털 문명 시대의 글로벌 거버넌스를 제공하지 못하고 있음은 객관적인 현실이라고 하겠다. 다시 말해 새로운 거버넌스를 창조해야 할 때이다. 국가 안에서의 헌법이나 국가 간의 조약이 아닐 것이다. 디지털 문명의 행성적 거버넌스, 홀어스의 한살림을 관장하는 룰 오브 코드(Rule of CODE)를 프로그래밍해야 할 것이다. 그 행성적 질서를 관장하는 새로운 조직이 필요하다. 잠정적으로 United Natures라고 표현하고 싶다. 동식물과 의사소통이 가능한 미래이기에 그들에게도 의사결정에 대한 참정권을 부여하는 것이다. 응당 에이전트로 부상한 활물의 집합체, AI도 동참해야 할 것이다. 이러한 합성 민주의 행성 기구를 가장 먼저 제안하고, 가장 앞서 그 거버넌스를 제공할 수 있는 소프트웨어를 개발하는 나라가 21세기를 선도해갈 것이다. 행성 차원의 한살림을 구현하는 OS를 창조해내는 것이다. 미국도 중국도 하지 못하고 있는 디지털문명의 패러다임을 창출해내는 것이다. 자유민주도 아니요, 사회민주도 아닌, 시민민주나 인민민주를 넘어선 우주만물의 민주, 우주적인 민주주의를 창발할 때이다. 새로운 사회계약론을 쓰고 천주와 군주와 민주를 지나 우주로 도약하는 것이다. 생태권과 인간권과 기술권을 공히 반영하고 서로가 서로를 견제하여 균형을 맞추고 조화를 일구는 진정한 삼권분립의 혼합정치로 진화하는 것이다. 20세기형 UN(United Nations)의 본부는 뉴욕에 자리한다. UN을 품고 있었기에 미국이 주도하는 '세계질서'가 80년 가까지 작동해 왔던 것이다. UN 2.0, OPEN UN, United Natures의 허브는 한반도 어딘가가 되면 좋겠다. 기왕이면 지하의 흔적이 남아 있는 강-호 라인, 강원도와 호남 어디라면 더더욱이나 좋겠다. 일백년 전 '만국활계 남조선'의 기개를 이어받아 일만년 후 '만물활계의 남조선' K가 되어가는 것이다. 테슬라는 자율주행, FSD를 제공한다. 팔런티어는 자율경영, 온톨로지를 서비스한다. 블랙록은 자율금융 소프트웨어, 알라딘을 보유하고 있다. 자율주행과 자율경영과 자율금융을 포월하는 행성 단위의 자율문명 OS를 개발해야 하는 것이다. HANSALIM, 혹은 SALIM이라고 그 소프트웨어의 이름을 지어주어도 좋을 것이다. 그 한살림의 거버넌스를 만들어내기 위해서는 행성 차원의 컴퓨팅이 필요하다. 행성 수준의 빅데이터가 있어야 한다. 그리고 무엇보다 행성 단위의 마인드부터 갖추어야 한다. 일체유심조, 한살림에 앞서 한마음부터 일으켜야 하는 것이다. 딥 마인드의 등장 이전에 딥 플래닛을 사유하고 실험한 초유의 한국인이 있었다. 인공지능에 앞서 인공위성이 있었다. 인공위성을 통하여 사피엔스 최초로 행성 차원의 행위예술을 선보였던 사람이다. 김지하가 미국 망명을 회유하는 유혹을 거절한 채 '뿌리 깊은 나무'를 고수했다면, 고향을 떠나 방랑하는 노마드로서 일찍이 행성을 주유천하했던 인물이다. 디지털 문명의 사제이자 샤먼, 백남준을 만날 차례이다.