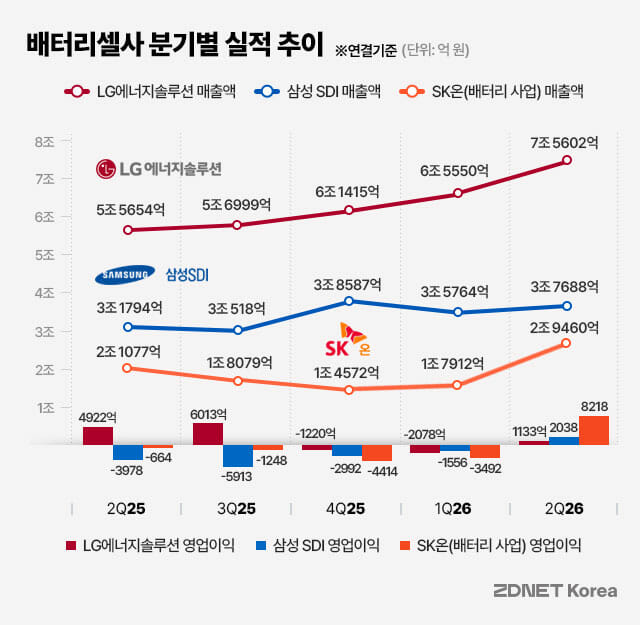
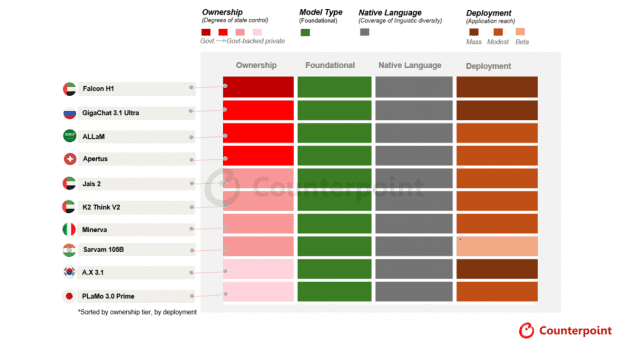
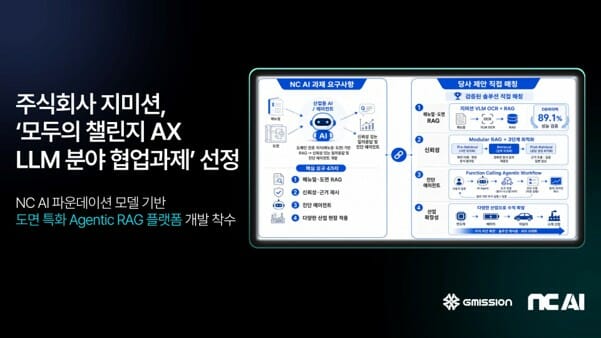
'평가'에서 '성장 관리'로...10배 도약 이끄는 GDR 프레임워크
지난 3편에서 우리는 1년에 한 번 과거의 잘못을 심판하는 낡은 목표관리제(MBO)가 시속 200km로 변하는 AI 시대의 속도를 어떻게 갉아먹고 있는지 살펴봤다. 목표 달성률에만 집착하는 평가 제도는 필연적으로 구성원들이 100% 달성 가능한 안전한 수치만 쫓는 하향 평준화를 유도한다. 목표의 불확실성이 극대화되고 실무의 실행 속도가 기계의 속도로 빨라진 시대에 조직은 근본적인 패러다임 전환을 감행해야 한다. 그것은 바로 1년에 한 번 과거의 잘못을 채점하는 '성과 관리'에서, 구성원 각자가 한계를 열어두고 폭발적으로 역량을 키우도록 돕는 '성장 관리'로 무게 중심을 완전히 이동해야 하는 것이다. AI가 요구하는 10배(10x)의 파괴적 도약은 지금 당장 구성원들이 가진 역량의 총합으로는 결코 도달할 수 없는 미지의 영역이다. 목표를 향해 달려가는 과정 그 자체가 구성원들의 압도적인 역량 성장으로 이어져야만 비로소 오를 수 있는 산이 된다. 이를 실현하기 위해 AI 시대의 조직은 낡은 MBO의 감옥을 부수고, 새로운 성장 관리 프레임워크인 'GDR(Goal - Direction - Role & Responsibility)'을 장착해야 한다. 종이 지도(MBO)를 버리고, 실시간 내비게이션(GDR)을 켜라 GDR은 조직의 목적지, 나아갈 방향, 그리고 실행 주체를 역동적으로 연결하는 성장 관리의 핵심 엔진이다. MBO가 연초에 인쇄해 둔 종이 지도를 맹신하며 달리는 방식이라면, GDR은 실시간 변수와 클럭 스피드에 맞춰 끊임없이 최적의 경로를 재탐색하는 내비게이션과 같다. 그 구체적인 세 가지 작동 원리는 다음과 같다. 1. Goal(목적지): 방어적 수치(KPI)가 아닌 '도착해야 할 명확한 목적지'의 공유 과거의 목표가 연말 보너스를 받기 위해 무조건 100%를 달성해야 하는 방어적인 수치(KPI)였다면, GDR에서의 Goal은 조직이 생존을 위해 반드시 뚫어내야 하는 근본적이고도 도전적인 '목적지'다. AI로 인해 기본 생산성이 상향 평준화된 시장에서 기업은 이전보다 훨씬 더 파괴적인 목표를 제시해야 한다. 리더는 구성원에게 숫자를 압박하는 대신, "이 거대한 목적지가 왜 우리 조직에 필요한지", "이것이 달성됐을 때 당신의 커리어에 어떤 대체 불가능한 무기가 될 것인지"를 명확하게 투영하고 공감대를 형성해야 한다. 2. Direction(방향과 전략): 실무 개입을 멈추고 '맥락'을 잇는 방향 설정 목적지가 정해지면 리더는 그곳을 향해 가기 위한 올바른 방향성과 세부 전략을 수립해야 한다. 여기서 주의할 점은 리더가 직접 노를 젓거나 선원들의 노 젓는 각도를 미세하게 교정하려 들어서는 안 된다는 것이다. 앞선 칼럼에서 강조했듯, 실무 산출물을 뽑아내는 실행 속도는 AI를 장착한 주니어들이 훨씬 빠르다. 리더는 지엽적인 개입과 통제를 상징하는 빨간펜을 내려놓고, 구성원들이 AI로 도출해 낸 파편화된 결과물들이 회사의 큰 전략적 맥락과 일치하는지, 타 부서와의 이해관계에 충돌은 없는지를 조율하는 맥락 디자이너로서 방향성을 끊임없이 영점 조절해 줘야 한다. 3. Role & Responsibility(동적 역할 분배): 박제된 직무기술서(JD)의 파괴와 '동적인 역할 분배' 전략이 세워졌다면 이를 수행할 수 있도록 구성원들에게 가장 적합한 역할과 책임을 분배해야 한다. 기술 트렌드와 필요한 스킬셋이 매달 바뀌는 시대가 됨에 따라, 연초에 문서로 고정해 둔 직무 기술서(JD)만으로는 부족해졌다. 리더는 팀원 개개인이 현재 어떤 역량을 새로이 발견하고 발휘하고 있는지를 실시간으로 파악해 그 시점의 전략 수행에 가장 최적화된 형태로 유연하게 R&R을 재배치해야 한다. 연속적 동기화와 1on1, GDR을 작동시키는 실무적 엔진 결국 GDR 프레임워크 아래에서 리더는 정답을 지시하고 결과를 통제하는 감시자가 아니다. 조직의 거대한 목표(Goal)를 향해 나아가는 과정에서, 구성원들이 궤도를 이탈하지 않도록 방향(Direction)을 맞추고, 각자의 잠재력이 가장 크게 폭발할 수 있는 역할(R&R)을 부여하는 고도화된 성장 조율자인 것이다. 하지만 GDR 프레임워크가 아무리 훌륭한 방향성을 제시한다 해도, 이를 일상에서 작동시킬 구체적인 실행 엔진이 없다면 결국 MBO와 다를 바 없는 또 하나의 피상적인 경영용어로 전락하고 만다. 목표의 불확실성이 크고 실무의 호흡이 빠를수록, 리더가 '조직의 목적지'와 '전략적 방향', 그리고 '구성원의 역할' 사이의 주파수를 맞추는 연속적인 동기화 과정이 꼭 필요하다. 그리고 이런 맥락에서 리더와 팀원이 정기적으로 마주 앉는 원온원(1on1)은 단순한 HR 제도를 넘어, GDR 프레임워크를 현장에 이식하는 가장 강력하고 필수적인 경영의 무기가 된다. 종이 위에 쓰인 GDR에 숨을 불어넣고, 1on1이라는 무기를 제대로 휘두르기 위해서는 리더십이라는 운영체제(OS)에 대한 근본적인 업데이트가 선행돼야 한다. 다음 5편에서는 1on1 현장에서 GDR을 완벽하게 실체화하는 AI 시대 리더의 새로운 생존 페르소나, 'ORBIT 리더십'의 5가지 핵심 요소를 본격 해부해 본다.