[현장] 국산 AI 반도체·클라우드 결합 '시동'…국가 인프라 강화 선언
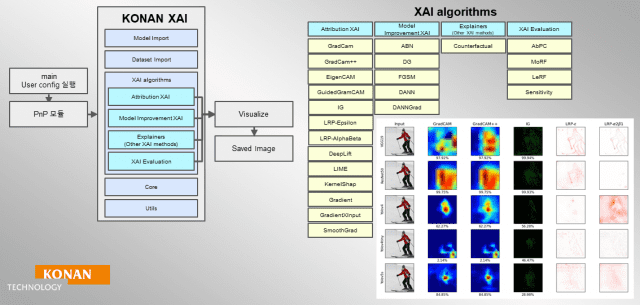
국산 인공지능(AI) 반도체와 클라우드 산업의 융합이 궤도에 올랐다. 초거대 AI 시대를 맞아 국가 인프라의 근간이 되는 클라우드가 스마트화와 지능형 자원 운영이라는 새로운 전환점을 맞이하면서 국산 기술 중심의 풀스택 생태계 구축이 본격화되고 있다. 오픈K클라우드 커뮤니티는 25일 서울 강남 과학기술회관에서 '오픈K클라우드 데브데이 2025'를 열고 국산 AI 반도체와 클라우드 융합 전략을 공유했다. 오픈K클라우드 커뮤니티에는 한국전자통신연구원(ETRI), 한국전자기술연구원(KETI), 이노그리드, 오케스트로, 경희대학교, 연세대학교, 한국클라우드산업협회(KACI), 퓨리오사AI 등 산·학·연 주요 기관이 공동 참여한다. 이번 행사는 커뮤니티의 첫 공식 기술 교류 행사로, 국산 AI 반도체를 중심으로 한 클라우드·소프트웨어(SW) 전주기 기술을 한자리에서 조망하며 국가 AI 인프라 경쟁력 제고 방안을 논의했다. ETRI 최현화 박사는 "이제 AI 서비스의 경쟁력은 모델을 누가 더 잘 만드느냐보다 누가 더 나은 인프라로 지속적으로 운영하느냐가 핵심"이라고 강조하며 클라우드의 대전환기를 진단했다. 최 박사는 최근 글로벌 거대언어모델(LLM) 발전의 특징을 멀티모달 확장, 컨텍스트 윈도우의 급격한 증가, 툴 연동 기반 정확도 향상으로 정리했다. 특히 메타가 공개한 오픈소스 LLM '라마'의 컨텍스트 윈도우가 1천만 토큰 수준으로 확장된 점을 언급했다. 그는 이러한 추세 속에서 국내 클라우드 산업이 ▲AI 가속기 이질성의 심화 ▲메모리 병목 문제 ▲추론 비용의 급증 ▲에이전트 폭증에 따른 관리 복잡도 증가 등 여러 난제를 동시에 마주하고 있다고 짚었다. 가장 먼저 꼽힌 것은 AI 가속기의 이질성 문제다. 엔비디아 그래픽처리장치(GPU) 중심 생태계가 유지되고 있지만 국내외에서 신경망처리장치(NPU)·AI칩·메모리 내 연산(PIM) 등 다양한 가속기와 인터커넥트 기술이 빠르게 등장하면서 단일 아키텍처에 의존하는 방식은 지속 가능하지 않다는 지적이다. 이어 LLM 추론의 핵심 병목으로 작용하는 '메모리 월'도 문제로 제기됐다. GPU 성능이 가파르게 증가하는 동안 메모리 기술 향상 속도는 더디기 때문이다. 최 박사는 SK하이닉스의 'AiMX', CXL 기반 차세대 메모리 사례를 언급하며 "AI 추론은 본질적으로 메모리 중심 작업이기에 차세대 메모리가 성능의 핵심을 좌우하게 될 것"이라고 말했다. LLM 스케일링 문제 역시 중요한 도전 과제로 다뤄졌다. 사용자 요구는 계속 높아지지만 단일 모델의 크기 확장에는 한계가 있어 여러 전문가 모델을 조합하는 '전문가 혼합(MoE)' 방식이 중요한 돌파구가 될 것이라고 강조했다. AI 모델마다 강점이 다른 만큼 다중 LLM 기반 지능형 추론은 필연적인 흐름이라는 설명이다. 추론 비용 문제도 빠지지 않았다. 최 박사는 "엔비디아 B200 급 GPU의 전력 소비가 1킬로와트(kW)에 이르는데, 이러한 DGX 서버 100대를 하루 운영하면 테슬라 전기차로 지구를 일곱 바퀴 도는 전력량에 해당한다"고 설명했다. 그러면서 "전력·비용 최적화는 하드웨어(HW) 스펙뿐 아니라 스케줄링, 클러스터 재구성이 필수"라고 말했다. 또 LLM·에이전트·데이터소스가 동적으로 연결되는 시대가 되면서 모니터링 복잡성이 기하급수적으로 커지고 있다는 점도 지적했다. 기존에는 레이턴시와 처리량을 중심으로 모니터링했다면 이제는 LLM의 할루시네이션 여부, 에이전트 간 호출 관계, 로직 변경 이력까지 관측해야 안정적 운영이 가능하다는 것이다. 이 같은 문제를 해결하기 위해 ETRI는 과학기술정보통신부가 추진하는 'AI 반도체 클라우드 플랫폼 구축 및 최적화 기술 개발' 과제에 참여했다. 이를 통해 ▲이종 AI 반도체 관리 ▲클라우드 오케스트레이션 ▲자동 디바이스 감지 ▲협상 기반 스케줄링 ▲국산 NPU 특화 관측 기술을 포함한 오픈소스형 '오픈K클라우드 플랫폼'을 개발 중이다. ETRI는 5년간 진행되는 사업에서 2027년 파라미터 규모 640억 LLM, 2029년 3천200억 LLM 지원을 목표로 풀스택 AI 클라우드 생태계를 구축할 계획이다. 오픈K클라우드 커뮤니티에 참여하는 퓨리오사AI, 이노그리드, 오케스트로도 이날 국산 AI 반도체와 클라우드 융합 생태계 활성화를 위한 기술 전략을 발표했다. 퓨리오사AI 이병찬 수석은 엔비디아 의존을 극복하기 위해 전력·운영 효율성을 높인 '레니게이드' 칩과 SW 스택을 소개했다. 이노그리드 김바울 수석은 다양한 반도체가 혼재된 클라우드 구조를 성능·전력·비용 최적화로 통합한 옵저버빌리티의 전략을 공유했다. 오케스트로 박의규 소장은 자연어 요구 기반 코딩과 자동화된 테스트·배포를 지원하는 에이전트형 AI SW 개발환경(IDE) 트렌드와 국내 시장의 변화에 대해 발표했다. 최 박사는 "앞으로 오픈K클라우드 플랫폼을 통해 국산 AI 반도체가 국가 핵심 인프라에 적용될 수 있는 계기를 만들겠다"고 강조했다. 이어 "아직 확정은 아니지만 정부가 추진하는 '국가AI컴퓨팅센터' 사업에 우리 플랫폼을 탑재할 수 있는 계기를 만들 것"이라며 "국산 AI 반도체 실사용자의 요구사항을 반영해 레퍼런스를 쌓아가는 것이 목표"라고 덧붙였다.