AI 스타트업 비드래프트, 독자 개발 파운데이션 모델 'Aether-7B-5Attn' 선봬
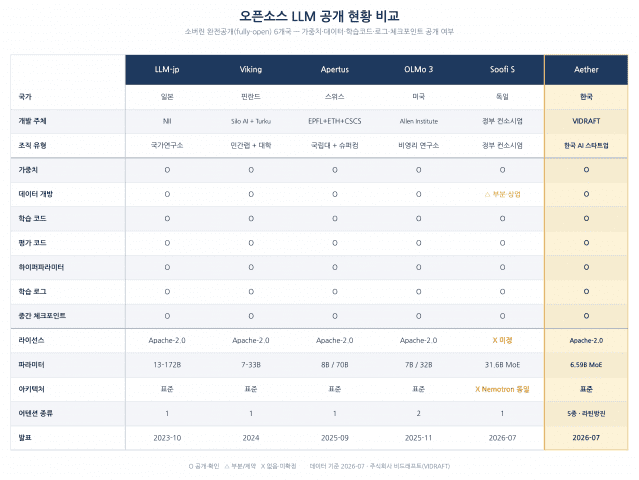
AI 스타트업 비드래프트(대표 김민식)는 독자 개발한 오픈소스 파운데이션 모델 'Aether-7B-5Attn'을 글로벌 AI 플랫폼 허깅페이스(Hugging Face)에 공개했다고 20일 밝혔다. Aether-7B-5Attn은 Apache-2.0 라이선스로 공개됐으며, 모델 가중치뿐 아니라 학습 데이터 레시피, 전체 학습 코드, 하이퍼파라미터, 학습 로그, 중간 체크포인트, 평가 코드까지 포함한 완전 공개형 모델을 지향한다고 회사 측은 설명했다. 비드래프트는 서울 소재 AI 딥테크 기업으로, Pre-AGI 수준의 AI 기술과 양자컴퓨터 기술 기반 물리·화학·생명·의약 등 연구개발 분야가 다양하다. 이 회사는 Darwin 모델 패밀리, AETHER 아키텍처, PROMETHEUS 월드모델, HEPHAESTUS 임바디드 AI로 이어지는 4계층 통합 AGI 시스템을 제시하고 있으며, 공식 홈페이지에서 'Darwin이 결과를 만들고, AETHER가 미래를 설계한다'는 방향성을 내세우고 있다. 비드래프트는 2026년 Darwin 계열 모델로 K-AI 리더보드 종합 1위, GPQA Diamond 90.9%, Polaris 글로벌 신약개발 리더보드 14관왕, 메타인지 리더보드 1위 등의 성과를 공개해 왔다. 또한 Darwin 모델 패밀리는 허깅페이스 누적 다운로드 100만 건을 돌파한 것으로 소개되고 있으며, 회사는 모델 개발뿐 아니라 추론 가속 엔진 VKAE, 경량 구동 엔진 VKUE 등 AI 인프라 기술도 함께 개발하고 있다. 그동안 AI 업계에서 '오픈소스 LLM'이라고 불린 다수 모델은 실제로는 가중치만 배포하는 '오픈 웨이트' 형태에 가까웠다. 가중치는 내려받아 실행할 수 있지만, 어떤 데이터로 어떻게 학습됐는지, 어떤 설정값과 코드로 만들어졌는지 확인하기 어려운 경우가 많았다. 이 경우 외부 연구자와 기업은 모델을 사용할 수는 있어도 동일한 과정을 재현하거나 독립적으로 검증하기 어렵다. Aether-7B-5Attn은 이러한 한계를 넘어서는 데 초점을 맞췄다. 공개 저장소만으로 학습 데이터 구성과 토큰화 과정, 학습 코드, 설정값, 로그, 평가 절차를 추적할 수 있도록 설계해 모델의 '결과'뿐 아니라 '제조 공정' 자체를 공개했다. 이는 Allen AI의 OLMo처럼 재현 가능성을 중시하는 오픈 파운데이션 모델 흐름과 같은 방향의 시도다. Aether-7B-5Attn은 총 65.9억 파라미터 규모의 전문가 혼합(MoE) 구조를 채택했으며, 토큰당 약 29.8억 파라미터만 활성화해 추론 효율을 높였다. 또한 Full Attention, Differential Attention, Sliding Window, NSA 계열 희소 어텐션, Hybrid 방식 등 5종의 이종 어텐션 메커니즘을 하나의 모델 안에 결합했다. 49개 층은 7×7 라틴 스퀘어 구조로 배치해 특정 어텐션 방식이 특정 깊이에 편중되지 않도록 설계했다. 학습은 엔비디아 B200 GPU 16장을 활용해 약 1442억 토큰 규모로 진행됐다. 데이터 구성은 수학 37.8%, 한국어 21.6%, 영어 21.6% 등을 포함하며, 영어 중심 모델이 아닌 한국어와 영어를 함께 고려한 독자 파운데이션 모델이라는 점도 특징이다. 베이스 모델과 인스트럭트 모델, 라이브 데모는 허깅페이스를 통해 공개됐다. 이번 공개는 '소버린 AI' 논의에서도 의미가 있다. 소버린 AI는 단순히 특정 국가나 기업이 모델 가중치를 보유하는 것을 넘어, 데이터·코드·학습 과정·평가 절차를 이해하고 필요할 경우 독립적으로 재현할 수 있는 능력에서 출발한다. 제조 공정 전체가 공개된 모델은 국가, 기업, 대학, 연구기관이 외부 빅테크에 대한 의존도를 줄이고 자신들의 언어·산업·보안 환경에 맞는 AI를 구축할 수 있는 기반이 된다. 완전 공개형 파운데이션 모델은 그동안 OLMo, Apertus, LLM-jp 등 해외 연구기관 또는 국가 단위 컨소시엄 중심으로 추진돼 왔다. 비드래프트는 단일 스타트업으로서 유사한 수준의 개방성과 재현 가능성을 지향하는 모델을 공개함으로써, 한국 AI 생태계에서도 독자 파운데이션 모델을 만들고 공개적으로 검증받는 흐름이 가능하다는 점을 보여줬다. 김민식 비드래프트 대표는 “남이 만든 가중치를 내려받는 것만으로는 AI 주권이 완성되지 않는다”며 “데이터와 코드, 학습 과정까지 공개해 누구나 다시 만들고 검증할 수 있게 하는 것이 오픈소스의 본질이자 소버린 AI의 출발점”이라고 전했다. 이어 “Aether-7B-5Attn 공개가 국내 AI 생태계에서 투명성, 재현성, 독자 모델 개발 역량에 대한 논의를 한 단계 끌어올리는 계기가 되길 바란다”고 덧붙였다.