"AI 도입보다 어려운 건 운영"…락플레이스, '통제형 자율 운영' 해법 제시
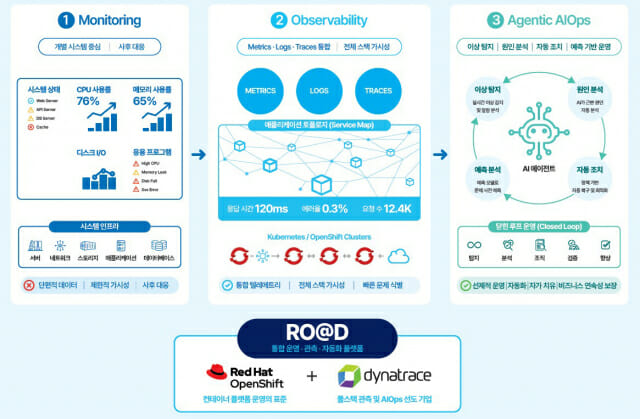
인공지능(AI) 확산이 기업 디지털 전환을 가속화하며 생산성을 끌어올리고 있다. 하지만 생성형 AI와 그래픽처리장치(GPU) 인프라, 클라우드 네이티브 기술 도입이 본격화되면서 IT 운영 환경은 갈수록 복잡해지는 추세다. 성능과 비용, 보안, 장애 대응을 아우르는 통합 운영 체계 구축이 새로운 과제로 부상하면서 안정적인 서비스 운영 역량이 기업 경쟁력을 좌우하는 핵심 요소로 떠오르는 모습이다. 22일 락플레이스는 이러한 변화에 대응하기 위해 플랫폼 표준화와 옵저버빌리티, AI옵스(AIOps), 자동화를 결합한 통합 운영 모델 '로드(RO@D)'를 앞세워 통제형 자율 운영 전략을 제시했다. 기업 IT 환경은 디지털 서비스 확대와 데이터 주권, 비용 최적화 요구에 따라 단일 데이터센터 중심 구조에서 하이브리드·멀티 클라우드 환경으로 빠르게 전환되고 있다. 특히 생성형 AI 도입이 본격화되면서 대규모 GPU 자원과 탄력적 확장성이 요구되는 AI 워크로드와 강력한 보안 및 안정성이 요구되는 기존 레거시 업무 시스템이 서로 다른 인프라 환경에서 분산 운영되는 사례가 늘고 있다. 여기에 쿠버네티스 기반 컨테이너 애플리케이션과 마이크로서비스 아키텍처(MSA) 확산까지 더해지면서 IT 운영 조직이 관리해야 할 복잡성은 한층 높아지는 상황이다. 문제는 AI 서비스가 기존 애플리케이션과 다른 운영 특성을 가진다는 점이다. AI 서비스는 GPU 사용량과 거대언어모델(LLM) 호출 횟수, 데이터 처리량, 추론 비용 등 다양한 요소가 복합적으로 작용하며 실시간 변동성을 만들어낸다. 단순히 서버 가동 여부를 확인하는 수준을 넘어 인프라와 애플리케이션, 데이터 파이프라인, 사용자 경험, 비용 구조까지 하나의 흐름으로 파악해야 하는 이유다. 이를 해결하기 위한 방안으로 다양한 옵저버빌리티 플랫폼이 등장하고 있다. 하지만 업계에서는 가시성 확보만으로는 복잡해진 운영 환경을 관리하는 데 한계가 있다는 지적도 나온다. 장애 발생 시 원인 분석과 조치, 검증 과정은 여전히 운영자의 경험과 수작업에 의존하는 경우가 많기 때문이다. 락플레이스는 단순 관측을 넘어 지능형 분석과 대응 자동화, 거버넌스까지 운영 전 과정을 하나의 흐름으로 통합하는 클라우드 네이티브 운영 모델 '로드'를 제시했다. 로드는 클라우드 플랫폼과 옵저버빌리티, 자동화를 단일 체계로 통합한 것이 특징이다. 가상머신(VM)과 컨테이너, AI 워크로드를 하나의 인프라 체계에서 관리할 수 있도록 구조화했다. 옵저버빌리티와 AI옵스(AIOps), 런북(Runbook) 자동화를 유기적으로 결합해 실시간 탐지부터 분석, 조치, 검증까지 이어지는 전방위적 운영 프로세스를 제공한다. 락플레이스는 엔터프라이즈 시장에서 검증된 '레드햇 오픈시프트' 기반 플랫폼으로 VM과 컨테이너, AI 워크로드를 일관된 기준으로 다룰 수 있는 토대를 마련했다. 여기에 '다이나트레이스(Dynatrace)' 기반 옵저버빌리티를 더해 서비스 흐름과 의존관계, 사용자 영향도, 인프라 상태를 입체적으로 분석한다. 더불어 운영자 승인과 정책 통제를 포함하는 '휴먼인더루프(Human-in-the-Loop)' 방식 통제형 자율 운영 모델로 안정성을 높였다. 반복 업무는 자동화하되 최종 의사결정과 통제 권한은 운영자가 보유함으로써 엔터프라이즈 환경에 필요한 거버넌스와 감사 가능성을 확보할 수 있도록 돕는다. 회사는 기업의 운영 성숙도에 맞춰 단계적으로 자율 운영 체계를 구축할 수 있도록 지원할 계획이다. 운영 진단과 플랫폼 표준화를 시작으로 옵저버빌리티 구축, AIOps 기반 원인 분석, 런북(Runbook) 자동화, 거버넌스 고도화 단계로 확장하는 방식이다. 락플레이스 관계자는 "AI 시대에는 단순히 인프라를 구축하는 것보다 복잡한 운영 데이터를 얼마나 빠르게 분석하고 실행 가능한 판단으로 연결하느냐가 중요하다"며 "로드를 통해 기업들이 클라우드 네이티브 환경에서 운영 가시성과 안정성, 효율성을 동시에 확보할 수 있도록 지원할 것"이라고 말했다.