정부 AI 데이터센터 1000조 투자 계획...산업계 환영 속 환경 관리 과제 부상
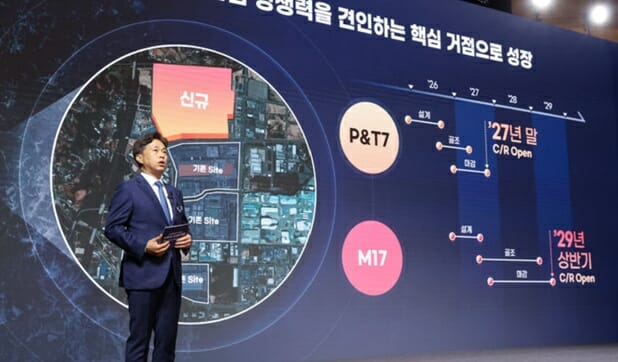
정부가 인공지능(AI) 데이터센터를 반도체에 이은 국가전략산업으로 키우기 위한 초대형 투자 계획을 내놓자 산업계와 시민사회 반응이 엇갈리고 있다. 소프트웨어(SW)·피지컬AI 업계는 AI 인프라 확충과 기술주권 확보를 위한 전략적 전환점으로 평가한 반면, 환경·시민단체는 전력·용수·탄소 배출 부담에 대한 관리 원칙이 부족하다고 지적했다. 30일 업계에 따르면 정부는 전날 서울 청와대 영빈관에서 열린 '대한민국 대도약 3대 메가프로젝트 국민보고회'에서 반도체, 피지컬AI, AI 데이터센터(AIDC)를 국가 성장 전략의 3대 축으로 제시했다. 정부는 2029년까지 8.4GW 규모 AIDC 구축에 550조원을 투입하고 2035년까지 10GW를 추가해 총 18.4GW 규모로 확대한다는 계획을 밝혔다. 누적 투자 규모는 1000조원 이상으로 제시됐다. 정부 구상은 AI 연산 수요 급증에 대응해 국내에 대규모 컴퓨팅 인프라를 확보하는 데 초점이 맞춰졌다. 수도권에 집중된 데이터센터를 충청 등 비수도권으로 분산하고, AI 반도체와 클라우드 솔루션 국산화도 함께 추진한다는 내용이다. 세액공제, 국민성장펀드, 초대형 테스트랩, AIDC 얼라이언스 등을 통해 국내 클라우드·AI 반도체 기업 참여를 넓히는 방안도 포함됐다. 배경훈 부총리 겸 과학기술정보통신부 장관은 AI 시장이 학습 중심에서 추론 중심으로 빠르게 이동하고 있다는 점을 강조했다. 대형언어모델을 개발하는 학습 인프라뿐 아니라 AI 서비스를 산업과 생활 현장에 적용하는 추론 인프라 경쟁력이 국가 AI 생태계의 핵심이 될 수 있다는 판단이다. 정부가 국산 신경망처리장치(NPU) 도입을 요청한 것도 AI 반도체와 데이터센터 수요를 국내 산업 기반으로 연결하려는 취지로 풀이된다. AI·SW 산업계는 이번 발표를 국내 기업의 AI 사업 기회 확대 계기로 받아들이고 있다. 대규모 AI 데이터센터와 초고속 네트워크, 피지컬AI가 함께 추진될 경우 클라우드, 보안, 데이터 관리, 품질관리, AI 서비스 개발 등 SW 기업이 참여할 수 있는 영역도 넓어질 수 있어서다. 인프라 구축이 해외 장비와 글로벌 클라우드 기업 중심으로 흘러가지 않도록 국내 중소 AI·SW 기업과 스타트업 참여 구조를 설계해야 한다는 요구도 나온다. 소프트웨어단체협의회는 이번 메가프로젝트가 AI 고속도로와 AI 데이터센터 등 핵심 인프라 확충을 통해 AI 데이터센터·초고속 네트워크·피지컬AI를 하나의 산업 생태계로 연결하는 미래 산업 전략이라고 평가했다. 또 정부 정책이 물리적 인프라 확충에 머무르지 않고 AI·SW 기술개발, 인재 양성, 제품·서비스 사업화, 공공·민간 수요 창출, 해외 진출 지원까지 균형 있게 확장되기를 기대한다고 밝혔다. 소단협 대표 회장사인 한국인공지능·소프트웨어산업협회(KOSA)는 "전 세계가 사활을 건 'AI 국가 대항전'의 한복판에 서 있으며, 오직 속도전만이 살 길이라는 정부의 절박한 시대 인식에 소단협 또한 깊이 공감한다"며 "이번 메가프로젝트가 대한민국의 기술 주권을 강화하고 지역과 산업이 함께 성장하며, AI·SW 산업의 글로벌 경쟁력을 높이는 역사적 계기가 되도록 산업계 역량을 모아 최선을 다하겠다"고 밝혔다. 피지컬AI 업계도 정부 발표에 힘을 실었다. 한국피지컬AI협회는 정부가 피지컬AI를 국가 핵심 전략산업으로 공식 제시한 점에 의미를 뒀다. 또 제조, 국방, 물류, 의료, 돌봄, 건설, 농업, 에너지, 도시 인프라 등 산업 현장에서 AI가 인식·판단·행동하는 체계가 확산되려면 AI 반도체, 온디바이스 AI, 로봇, 센서, 통신, 디지털트윈, 행동데이터, AI 데이터센터가 풀스택 생태계로 연결돼야 한다고 설명했다.유태준 한국피지컬AI협회장은 "대한민국은 세계적 수준의 제조 기반, 반도체 역량, ICT 인프라, 로봇·모빌리티 산업, 조선·자동차·방산 등 주력 산업 경쟁력을 보유하고 있다"며 "이러한 강점을 피지컬AI와 결합한다면 대한민국은 글로벌 AI 경쟁에서 새로운 주도권을 확보할 수 있을 것"이라고 말했다. 반면 AI 데이터센터 확대가 국가 전략산업 육성이라는 명분만으로 추진돼서는 안 된다는 주장도 나왔다. 대규모 인프라 투자가 지역 전력망과 수자원, 탄소 배출 부담으로 이어질 수 있는 만큼 공적 관리 기준을 먼저 세워야 한다고도 강조했다.특히 녹색전환연구소, 참여연대, 환경정의는 공동 성명에서 오는 2029년 8.4GW 규모 데이터센터가 들어설 경우 2035년까지 추가 온실가스 배출량이 8500만 톤에 이를 수 있다고 주장했다. 이들 단체는 정부가 전력과 용수, 부지, 규제완화 지원을 앞세우면서 기업의 재생에너지 사용 의무, 에너지·물 효율 기준, 정보 공개 등 책임 장치를 충분히 제시하지 않았다고 봤다. 전력 공급 방식에 대한 우려도 제기됐다. 시민사회는 원전과 소형모듈원전(SMR), 액화천연가스(LNG), 재생에너지 등을 함께 활용하겠다는 접근이 탄소중립 목표와 충돌할 수 있다고 지적했다. 비수도권 분산 전략 역시 지역균형발전 효과로 이어지려면 주민 수용성, 환경적 지속가능성, 지역 에너지 우선 소비 원칙이 함께 설계돼야 한다는 입장이다. 업계에선 이 같은 분위기를 두고 AI 인프라 경쟁이 산업 진흥을 넘어 전력망, 용수, 탄소 배출 관리 문제와 함께 다뤄져야 한다는 점이 드러난 것이라고 평가했다. 이에 정부가 AI 데이터센터를 국가전략산업으로 키우려면 대규모 투자 유치와 함께 전력사용효율(PUE), 물사용효율(WUE), 재생에너지 조달, 지역 인허가 기준을 제도화하는 작업도 병행돼야 할 것으로 보인다. 녹색전환연구소·참여연대·환경정의는 "AI 데이터센터의 입지와 운영을 시장에 맡기는 것이 아니라 기후와 환경, 시민에게 미치는 영향을 규율하는 제도가 필요하다"며 "재생에너지 사용 의무화, 비수도권 분산 및 지역 에너지 우선 소비, PUE·WUE 규제, 국가와 지자체 주도의 엄격한 인허가 및 공적 관리 체계를 전면 도입해야 한다"고 밝혔다.