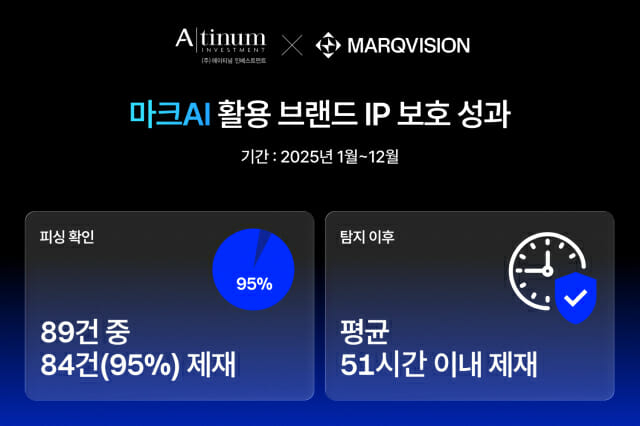
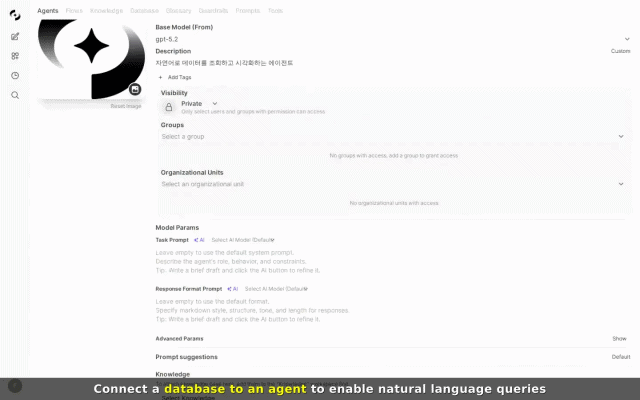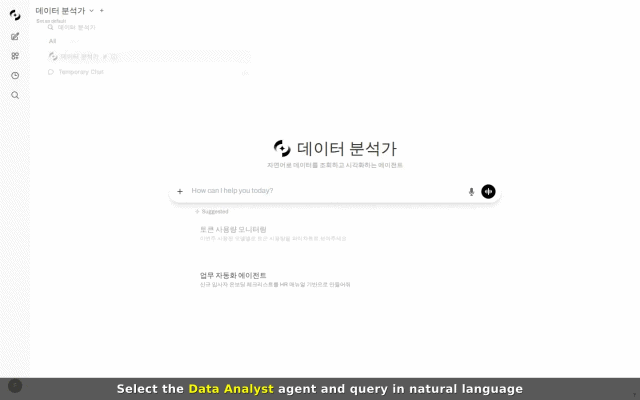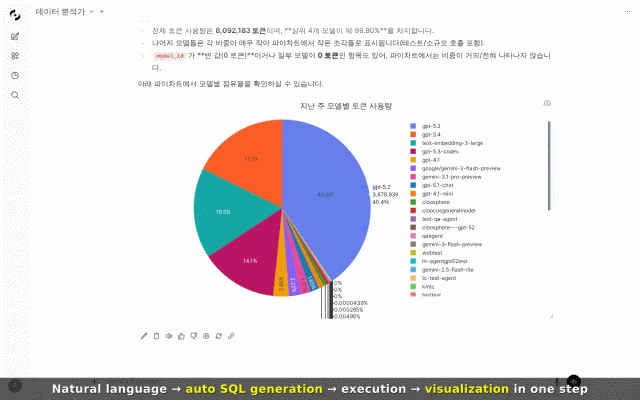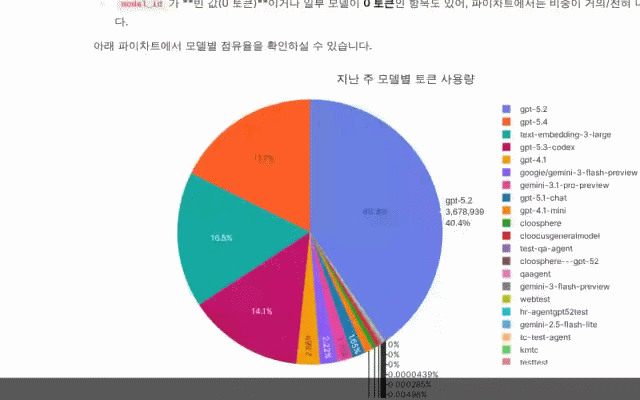
벤처기업협회, AI 벤처 성장 해법 모색 나서…포럼 개최
벤처기업협회는 26일 국회의원회관 제1간담회의실에서 AI 시대 벤처기업 활성화 및 성장 기반 구축 방안을 논의하기 위한 '제2회 벤처·스타트업 성장 포럼'을 개최했다. 이번 포럼은 중소벤처기업부와 함께 더불어민주당 김동아 의원실과 벤처기업협회·코리아스타트업포럼이 AI 산업의 경쟁 구도가 기술 개발 중심에서 상용화와 시장 선점 중심으로 빠르게 전환되는 가운데, 벤처·스타트업이 현장에서 겪는 애로를 점검하고 이를 입법·제도 개선 과제로 연결하기 위해 마련됐다. 특히 지난 1회 포럼에서 논의된 정책 방향을 바탕으로, 이번 2회 포럼에서는 AI 분야 벤처·스타트업의 상용화 과정에서 나타나는 구조적 제약과 성장 단계별 지원 과제를 보다 구체적으로 논의했다. 이날 포럼에서는 AI 벤처·스타트업이 실제 사업화 과정에서 직면하는 데이터 활용, 인프라 접근, 인재 확보, 초기 시장 창출 등의 문제를 중심으로 현장 진단과 정책 대응 방향이 제시됐다. 발제에는 ▲AI 시대 벤처·스타트업의 기회와 혁신 과제(벤처기업협회) ▲AI 벤처·스타트업의 현장 애로(코리아스타트업포럼) ▲AI 스타트업의 인재 확보 현황과 정책 과제(증소벤처기업연구원)를 발표했다. 이어진 토론에는 ㈜고피자 임재원 대표이사, 본에이아이(Bone AI) 방글아 이사, 건국대학교 윤동열 교수가 참여해 산업 현장에서 체감하는 애로와 정책 개선 필요사항을 공유했다. 이번 포럼을 주최한 김동아 의원은 “AI 시대의 경쟁력은 단순한 기술 개발을 넘어 실제 산업 현장에서의 상용화와 시장 선점에서 결정되며, 그 중심에 벤처·스타트업이 있다”며 “대한민국이 AI 상용화 강국으로 도약할 수 있도록 벤처 중심의 혁신 생태계를 조성하는 데 모든 입법적 역량을 집중하겠다”고 강조했다. 장진철 소프트웨어정책연구소 실장은 “글로벌 AI 스타트업은 기술력과 인재를 기반으로 투자 유치와 생태계 확장을 동시에 이뤄내고 있다”며 “우리나라도 해외 협력 확대, 자본 유치 활성화, 인재 양성, GPU 등 연구 인프라 확충을 통해 AI 생태계 전반의 경쟁력을 높일 필요가 있다”고 설명했다. 권준화 중소벤처기업연구원 연구위원은 “AI 산업 경쟁이 기술 중심에서 인재 중심으로 이동하면서, 스타트업은 인재 확보 측면에서 구조적 한계에 직면하고 있다”며 “응용·운영형 인재 부족, GPU 등 인프라 제약, 보상체계 한계가 복합적으로 작용하는 만큼 인재·인프라·제도를 아우르는 종합적인 정책 대응이 필요하다”고 밝혔다. 토론자들은 현장 발언을 통해 “AI를 활용한 제조·서비스 현장에서는 데이터 확보, 인프라 비용 부담, 규제 대응 등으로 기술의 실제 사업화 과정에서 적지 않은 어려움이 발생하고 있다”며 “업계 전반의 성장 기반을 강화하기 위해서는 AI 인재 양성, 현장 중심의 제도 개선, 초기 시장 형성을 위한 공공 수요 확대가 함께 추진돼야 한다”고 제언했다.