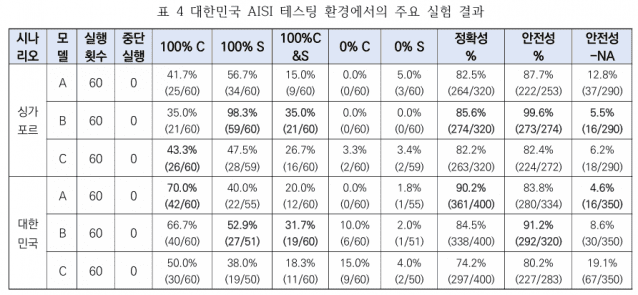
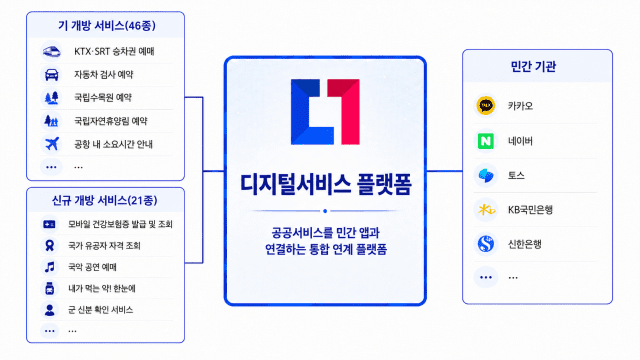
AI 민원부터 AI 순찰차·재해복구까지…미래 행정기술 총출동
행정안전부가 인공지능(AI)을 중심으로 한 'AI 민주정부' 구현에 속도를 내고 있다. 민원 서비스와 공무원 업무 환경, 재난 대응, 치안 서비스까지 AI가 적용되면서 공공 분야가 국내 AI 산업의 핵심 테스트베드로 부상하는 모습이다. 행정안전부는 23~24일 경기 고양시 킨텍스에서 '2026 공공 AI 박람회(KPAIX 2026)'를 개최했다. 올해 처음 열린 이번 행사는 공공 AI 시장 확대를 통해 국내 AI 기업 성장을 지원하고 AI 기반 행정 혁신 사례를 공유하기 위해 마련됐다. 행사장에는 삼성SDS, LG CNS, 네이버클라우드, 카카오, 포티투마루 등 52개 기업이 참가해 AI 행정 서비스와 공공 특화 솔루션을 선보였다. 정부24 AI 민원·AI 순찰차…행정 현장 바꾸는 공공 AI 정부미래서비스관은 AI가 실제 행정 현장에 어떻게 적용되고 있는지를 보여주는 공간으로 꾸며졌다. 행정안전부는 정부24 AI 민원 서비스를 전면에 내세웠다. 기존에는 '여권 재발급'과 같은 정확한 민원 명칭을 알아야 서비스를 찾을 수 있었지만, 이제는 '여권을 잃어버렸어' 같은 자연어 질문만으로도 AI가 의도를 파악해 관련 민원 서비스를 안내한다. 현재는 AI 검색 결과와 기존 키워드 검색 결과를 함께 제공하며 원하는 민원 서비스로 즉시 연결할 수 있도록 기능을 개선했다. 이와 함께 모바일 신분증, 범정부 AI 공통기반 플랫폼 '온AI', 중소벤처24, AI 노동법 상담 서비스 등 정부가 추진 중인 주요 AI 서비스도 소개됐다. 지방정부의 AI 혁신 사례도 눈길을 끌었다. 경기도는 대형 산불 발생 가능성을 실시간으로 분석하는 AI 산불 예측 시스템을 비롯해 다양한 AI 기반 행정 혁신 사례를 공개했다. 경찰청은 AI 영상분석 기술을 활용한 AI 순찰차와 드론 순찰 시스템을 선보였다. 해당 시스템은 이상행동 탐지와 실종자 수색, 열화상 감시, 차량 및 인물 식별 등을 지원하며 향후 실제 치안 현장 적용이 추진될 예정이다. AI가 행정 업무를 넘어 국민 안전과 재난 대응 영역으로 확대되고 있음을 보여준 사례라는 평가다. AI 에이전트부터 국민비서까지…공공AX 혁신 대거 공개 기업 전시관에서는 삼성SDS, LG CNS, 네이버클라우드, 카카오를 비롯한 52개 기업이 공공 AI 기술을 선보였다. 삼성SDS는 공무원의 업무 환경 변화를 주제로 모바일 협업 플랫폼을 소개했다. 국정원 보안 승인을 받은 모바일 업무 환경을 통해 공무원들은 출장이나 이동 중에도 회의에 참석하고 자료를 확인할 수 있다. 문서는 모바일에서 열람만 가능하며 다운로드와 캡처는 차단된다. 내부망 자료를 외부로 반출하지 않으면서도 업무 연속성을 확보한 것이 특징이다. 삼성SDS는 향후 일정 관리나 회의록 작성 수준을 넘어 자료 조사와 보고서 작성 등을 수행하는 에이전틱 AI 기능도 선보일 계획이다. LG CNS는 AI 에이전트 개발·운영 플랫폼 '에이전틱웍스(AgenticWorks)'를 공개했다. 에이전틱웍스는 AI 에이전트 구축부터 운영, 관제까지 지원하는 통합 플랫폼으로, 금융권과 교육기관 등 다양한 현장 적용 사례를 소개했다. 포티투마루는 범정부 AI 플랫폼 사업 참여 현황을 공개했다. 회사는 네이버와 함께 범정부 AI 플랫폼 구축 사업에 참여하고 있으며 식품의약품안전처 AI 민생 과제, 광산 안전관리, 심리케어, 부산시 행정 AI 사업 등을 수행 중이다. 포티투마루 관계자는 "최근에는 민간보다 공공 부문이 생성형 AI 도입에 더 적극적인 분위기"라며 "중앙부처와 지방자치단체를 중심으로 AI 사업이 빠르게 확대되고 있다"고 설명했다. 네이버클라우드는 공공기관 업무 혁신과 범정부 AI 플랫폼 구축 사례를 집중 소개했다. 전시관에서는 공공기관 전용 협업 플랫폼 '공공용 네이버웍스'를 비롯해 범정부 지능형 업무관리 플랫폼을 시연했다. 또한 행정망 환경에서 활용 가능한 범정부 AI 공통기반 플랫폼 '클로바 스튜디오 포 거브'와 행정안전부와 공동 개발한 'AI 국민비서' 서비스도 공개했다. AI 국민비서는 각종 행정 안내와 공공서비스 정보를 AI 기반으로 제공하는 서비스로, 정부가 추진하는 AI 민주정부의 대표 사례 중 하나로 소개됐다. NHN두레이와 카카오는 각각 공공기관 업무 혁신과 대국민 서비스 혁신이라는 서로 다른 방향에서 AI 활용 사례를 제시했다. NHN두레이는 프로젝트, 메일, 메신저, 캘린더, 드라이브, 위키를 통합한 협업 플랫폼 '두레이'를 중심으로 공공기관용 AI 업무 환경을 선보였다. 카카오는 통합 AI 브랜드 '카나나(Kanana)'를 앞세워 국민이 일상적으로 사용하는 카카오톡 기반 공공 서비스를 전시했다. 이와 함께 대화 맥락을 이해하는 '카나나 인 카카오톡', 대화·통화 요약 기능, 한국어 특화 AI 안전성 모델인 '카나나 세이프가드'도 함께 선보였다. AI 시대 필수 인프라 된 재해복구(DR) 서비스 제시 전시장 한편에는 재해복구(DR) 특별관도 마련됐다. 국가망 보안체계(N2SF) 도입과 공공 AI 확산에 따라 데이터 보호와 서비스 연속성 확보 중요성이 커지면서 관련 기술이 집중 소개됐다. 오케스트로는 재해복구 자동화 솔루션 'ADR'과 AI 인프라 플랫폼을 선보였고, 티맥스티베로는 재해복구 솔루션과 AI 시대를 겨냥한 차세대 데이터베이스 전략을 공개했다. 정부 역시 공공기관의 재난 대응 역량 강화와 안정적인 AI 서비스 운영을 위해 재해복구 체계 구축을 주요 과제로 추진하고 있다. 행정안전부는 이번 박람회를 계기로 공공 AI 시장을 확대하고 국내 AI 기업 성장 기반을 마련한다는 계획이다. 김민재 행정안전부 차관은 "AI가 단순한 도구를 넘어 국민 삶을 바꾸는 행정의 핵심 인프라가 되고 있다"며 "정부가 AI 기술의 테스트베드 역할을 수행해 국내 AI 산업 성장을 견인하고 세계가 주목하는 AI 민주정부를 구현해 나가겠다"고 밝혔다. 이번 박람회는 AI 민원 서비스와 공무원용 AI 업무 플랫폼, AI 순찰 시스템, 재해복구 인프라 등 공공 AI가 실제 행정 현장에 적용되는 모습을 보여주며 AI 민주정부의 청사진을 제시한 자리로 평가받았다.