'갤S26' 오래 쓸수록 안다…스냅드래곤 8 엘리트 5세대의 진가
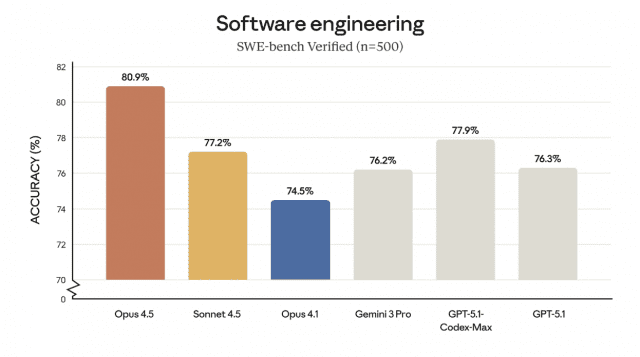
올해 초 출시된 삼성전자 '갤럭시 S26' 시리즈가 흥행가도를 달리고 있다. 특히 최상위 모델인 울트라 모델의 경우, 국내 사전 판매량에서 70%의 비중을 차지할 정도로 압도적인 선호도를 자랑한다. 갤럭시S26 울트라의 성공을 이끈 주역은 단연 퀄컴 '스냅드래곤8 엘리트 5세대'다. 해당 칩셋은 스마트폰의 두뇌 역할을 담당하는 모바일 AP(애플리케이션 프로세서)다. 갤럭시 S26 일반·플러스 모델은 삼성전자의 자체 칩셋인 '엑시노스'를 일부 탑재했으나, 울트라 모델 만큼은 스냅드래곤이 공고한 입지를 다지고 있다. 장시간 게이밍·AI 작업도 거뜬…스냅드래곤 8 엘리트 5세대의 힘 스냅드래곤 8 엘리트 5세대의 실제 성능을 확인하기 위해 FPS 모바일 게임 '레인보우 식스 모바일'을 실행했다. 게임 내 그래픽은 '매우 높음', FPS는 최대 60으로 설정했다. 또한 갤럭시 기기 내 게임 부스터 기능을 통해 성능을 우선하도록 했다. 그 결과 갤럭시S26은 화면 녹화 기능을 동시에 실현 중임에도 매우 쾌적한 게이밍 환경을 지원했다. 시스템 모니터링 기능에 따르면 FPS는 대부분 60을 유지했고, CPU 부하는 30%대, GPU는 60~70%대를 나타냈다. 1시간 넘게 이어진 게임 및 화면 녹화에도 기기의 발열은 적절한 수준을 유지했다. 게임의 요구 사양 및 최적화 여부에 따라 차이는 있겠으나, 최신 게임을 즐기는 데 전반적으로 무리가 없을 것으로 보인다. 이는 상시 일정한 성능을 유지하도록 설계된 스냅드래곤 8 엘리트 5세대의 힘이다. 해당 칩셋은 퀄컴 오라이온 CPU를 기반으로 한 2+6 옥타코어 구조를 채택했다. 최대 4.74GHz 프라임 코어 2개와 최대 3.62GHz 퍼포먼스 코어 6개로 구성되며, 이전 세대 대비 약 19% 성능이 향상됐다. 슬라이스드 아키텍처 기반 아드레노(Adreno) 840으로 재설계된 GPU는 작업 부하에 따라 연산 유닛을 병렬로 활용하는 구조를 갖추고 있다. 그래픽 성능은 24% 향상되고, 전력 효율은 20% 개선됐다. 또한 최첨단 파운드리 공정인 3나노미터(nm)을 적용해, 매우 강력한 성능을 뒷받침한다. 이를 통해 장시간 사용이나 멀티태스킹 환경에서도 고성능 어플리케이션을 안정적으로 구동할 수 있다는 게 퀄컴의 설명이다. 칩셋의 성능을 가늠해볼 수 있는 긱벤치6 테스트 결과는 싱글코어 3632점, 멀티코어 1만1067점으로 나타났다. GPU는 2만2604점이다. 갤럭시S25 울트라(싱글코어는 2852점, 멀티코어 9433점) 대비 큰 폭의 향상이 있던 것으로 분석된다. 그래픽 성능을 검증하는 3D마크 와일드 라이프 익스트림의 경우 7345점을 기록했다. 평균 FPS는 43.99다. 해당 벤치마크 테스트가 집계한 전체 결과 중 상위 2%에 해당하는 수치다. 갤럭시S26 시리즈의 핵심 무기인 에이전트 AI 기능도 완벽히 지원한다. 스냅드래곤 8 엘리트 5세대는 최신 퀄컴 AI 엔진으로 이전 대비 39% 향상된 헥사곤 (Hexagon) NPU를 갖췄다. 동시에 CPU 내에서 AI 연산을 보조하는 QMX(Qualcomm Matrix Extensions) 엔진은 소규모 AI 연산까지 빠르게 처리한다. 대형 모델은 NPU가, 경량 추론은 NPU와 QMX 엔진이 담당하는 이기종(Heterogeneous) 컴퓨팅 구조로 다양한 에이전트 AI 기능을 효율적으로 처리할 수 있다. APV 코덱 지원…전문가 수준 영상 촬영 가능케 해 스냅드래곤 8 엘리트 5세대는 모바일 플랫폼 최초로 APV(Advanced Professional Video) 코덱 기반의 영상 촬영을 제공하는 칩셋이기도 하다. APV는 전문 영상 제작을 위해 설계된 코덱으로, 고비트레이트 레코딩과 손실이 거의 없는 화질을 제공한다. 전용 하드웨어 인코딩·디코딩을 통해 스마트폰에서도 시네마급 영상 처리가 가능하다. 육안상 RAW에 가까운 화질을 유지하며 컬러 그레이딩이나 노출 보정과 같은 후반 작업에서도 디테일 손실이 거의 없다. 실제로 APV 코덱을 활성화해 서울 여의도 일대의 야경을 촬영해보니, 별도의 기기나 어플이 없이도 매우 선명한 영상을 찍을 수 있었다. 빠르게 달리는 차량도 빛 번짐없이 포착했다. 영상 촬영의 최대 화질은 8K에 달하며, UHD 화질에서는 최대 60FPS의 프레임을 지원한다.