젠슨 황 "SK하이닉스 캐파 2배 확대로는 불충분"
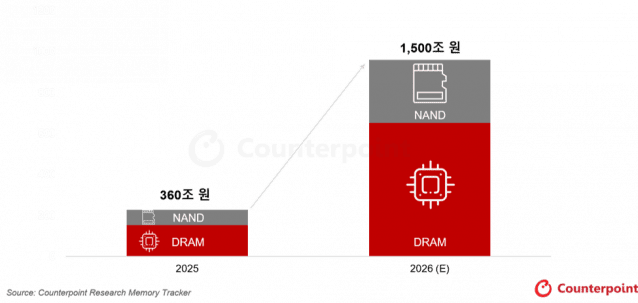
젠슨 황 엔비디아 최고경영자(CEO)가 SK하이닉스의 장기 생산능력 확대 계획에 대해 "충분치 않다"고 말했다. 앞서 최태원 SK그룹 회장은 "앞으로 5년 안에 전체 웨이퍼 생산능력을 2배로 늘릴 것"이라고 말한 바 있다. 8일 젠슨 황 CEO는 서울 중구 신라호텔에서 열린 '코리아 AI 에코시스템 리셉션' 후 기자들과 만나 "(SK하이닉스 계획은) 충분치 않다고 생각한다"며 "우리는 스마트(smart)해져야 한다. 엔비디아는 SK가 생산하는 모든 메모리를 최대한 똑똑하게 사용할 것"이라고 밝혔다. 그는 "엔비디아는 인공지능(AI) 가속기 시장 80%를 점유하고 있고, 시장 점유율을 계속 확대하고 있다"며 "우리는 매년 거의 100%씩 성장하고 있고, 성장은 더 가속되는 것으로 보인다"고 강조했다. 황 CEO는 "AI 붐(Boom)은 거대하다. AI가 드디어 유용해졌기 때문이다. AI는 이제 우리가 소프트웨어 프로그래밍을 효과적으로 할 수 있도록 돕는다"며 "전 세계에서 소프트웨어 코딩을 사용하지 않는 기업은 없다"고 설명했다. 그는 "AI는 수익성이 좋다. AI가 너무 유용하기 때문에 기업들은 AI를 사용하기 위해 기꺼이 프리미엄을 지불한다"며 "무언가가 수익성이 높다면, 그것을 더 많이 만들고 싶어진다. 아주 가까운 미래에 AI가 얼마나 믿을 수 없을 정도로 수익성이 높은지 깨닫게 될 것"이라고 덧붙였다. 황 CEO는 이번 방한 최대 성과로 국내 기업들과 협력을 꼽았다. 그는 "우리는 SK하이닉스와 매우 긴밀하게 협력해 왔다. 그들(SK)의 기술과 우리(엔비디아)의 기술이 매우 긴밀하게 작동하도록 만들 것"이라고 말했다. LG와 현대자동차, 삼성전자, 네이버도 언급했다. 황 CEO는 "데이터센터 기술, 데이터센터 아키텍처, 로보틱스 분야에서 LG와 장기간 같이 작업했다"며 "자율주행과 로보틱스 기술 분야에선 현대와 함께 일했고, 삼성전자와도 정말 오랫동안 함께 했다. 네이버와도 함께 일한지 오래됐다"고 설명했다. 황 CEO는 이날 행사에서 "지금이 바로 한국의 시간"이라며 이 기회를 살려야 한다고 조언했다. 그는 "한국은 올바른 문화 기반과 산업 기반, 지정학 위치를 모두 갖췄다"며 "지금이 이것들을 활용할 절호의 기회"라고 강조했다. 간담회에는 삼성전자와 SK하이닉스, SK텔레콤, 현대차그룹, LG전자, 네이버, 크래프톤 등 주요 대기업이 참석했다. 업스테이지, NC AI, 프렌들리AI, 트웰브랩스, 파일러, 노타 등 AI 스타트업과 두산로보틱스, 리얼월드, 로보티즈, 엔닷라이트, 에이로봇 등 로봇·피지컬 AI 기업도 함께 했다.