두산, AI 가속기용 시장 공략…美 디자인콘 참가
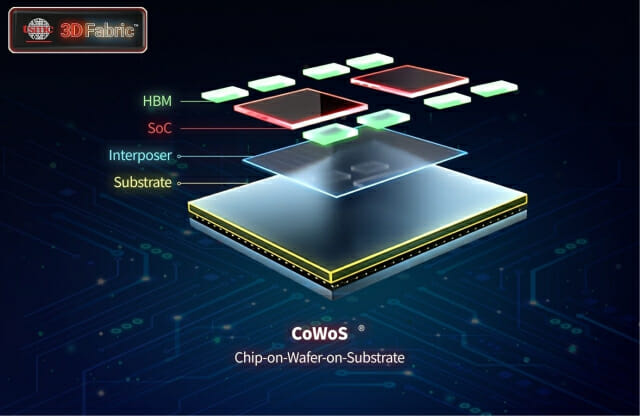
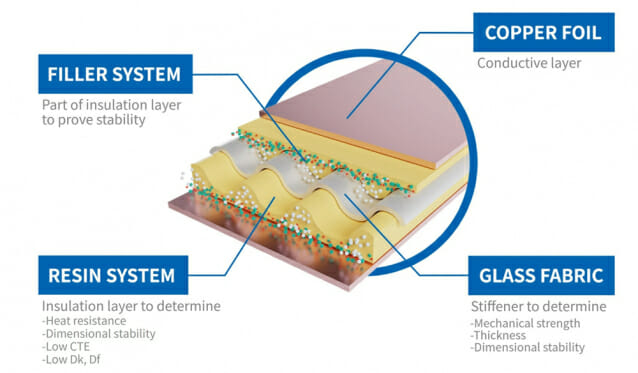
두산이 하이엔드 동박적층판(CCL)을 앞세워 인공지능(AI) 가속기, 고속통신네트워크 시장을 노린다. 두산은 오는 29일부터 이틀간 미국 산타클라라에서 열리는 '디자인콘 2025'에 참가한다고 26일 밝혔다. 올해 30주년을 맞는 디자인콘은 미국 최대 규모 통신·시스템 설계 분야 전시회로, 올해는 CCL, 전자회로기판(PCB), 통신장비 등과 관련한 160여 개 기업이 참가해 최첨단 기술과 제품을 선보인다. 이번 전시회에서 두산은 AI 가속기용 CCL과 데이터센터(라우터, 스위치, 서버)에 적용되는 고속통신네트워크용 CCL을 중점적으로 소개하며, 기술력과 연구개발(R&D) 역량을 강조할 계획이다. CCL은 동박과 레진 및 보강기재 등이 결합된 절연층으로 구성되며, PCB에 사용되는 핵심 소재다. 정밀한 레진 배합과 고도화된 제조 기술을 활용한 고성능 CCL 기반 고객 맞춤형 솔루션으로 시장에서 차별화된 경쟁력을 인정받고 있다고 회사 측은 설명했다. 특히, 시장에서 최근 큰 관심을 받는 AI 가속기는 AI 성능을 높이기 위해 특화된 첨단 시스템 반도체다. 머신러닝, 딥러닝에 필요한 데이터 학습, 추론 등의 핵심 연산기능을 정확하고 빠르게 처리하도록 돕는다. 두산의 AI 가속기용 CCL은 저유전, 저손실 특성을 지니고 있어 고주파영역에서도 대용량 데이터를 고속으로 공급할 수 있다. AI, 사물인터넷(IoT), 자율주행 등 대용량 데이터 처리량이 급증하면서 데이터센터와 클라우드에서 400GbE(기가비트 이더넷) 이상의 통신속도가 요구된다. 두산은 이번에 선보이는 800GbE 고속통신네트워크용 CCL은 차세대 네트워크 통신 규격에 맞춘 제품으로, 데이터 처리 속도가 빠르고 통신 지연율도 최소화할 수 있다고 설명했다. 또한 차세대 1천600GbE 통신네트워크용으로 개발 중인 CCL도 이번 전시회에서 소개할 예정이다. 이 외에도 MEMS 오실레이터(미세전자기계시스템 발진기)도 함께 선보인다. 이 제품은 반도체 제조공정의 미세가공 기술을 응용한 것으로 전자기기, 통신시스템 등의 내부 신호 주파수를 발생시키는 핵심 부품이다. 캐나다 스타세라와 공동 개발한 두산의 MEMS 오실레이터는 ▲출력 주파수 변경 가능 ▲하나의 장치에서 2개 주파수 동시 출력 ▲외부 충격이나 전자파에 대한 높은 내구성 ▲온도·습도 변화에도 안정적인 성능 유지 ▲낮은 전력 소모량 등의 특성을 갖고 있다. 또한 소형으로 공간효율성이 좋아 웨어러블, 모바일 기기 등에도 적합하며, 올해 상반기 양산을 앞두고 있다. 두산 관계자는 "우수한 제품 기술력과 R&D 역량 뿐만 아니라 개발 단계부터 샘플 테스트, 계약까지 신속한 고객 맞춤형 대응 체계를 구축하고 있다"면서 "이번 전시회를 통해 신규 고객 발굴과 시장 확대를 위한 마케팅 활동에 박차를 가할 것”이라고 말했다.