행동하는 AI의 시대…AI 에이전트의 구조, 발전, 그리고 미래
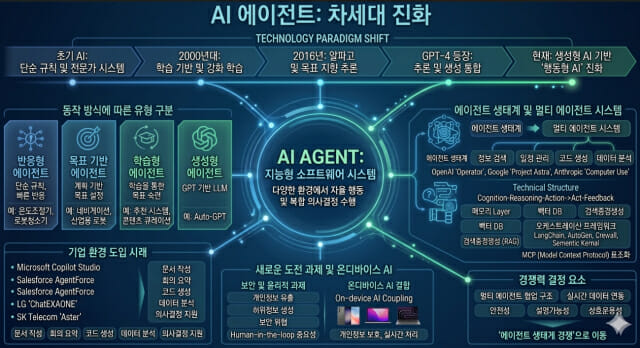
인공지능(AI) 에이전트는 다양한 환경에서 자율적으로 행동하며 복합적인 의사결정을 수행하는 지능형 소프트웨어 시스템을 의미한다. 최근에는 단순한 자동화 도구를 넘어, 스스로 목표를 설정하고 계획을 수립하며 외부 도구와 연동해 실행까지 수행하는 차세대 AI 기술로 주목받고 있다. 특히 생성형 AI와 대규모 언어모델(LLM)의 발전은 AI 에이전트를 기존의 단순 챗봇 수준에서 벗어나 실제 업무를 수행하는 '행동형 AI'로 진화시키고 있다. AI 에이전트는 구조와 동작 방식에 따라 다양한 유형으로 구분된다. 가장 기본적인 형태는 현재 환경에 즉각 반응하는 반응형 에이전트로, 온도조절기나 로봇청소기처럼 단순 규칙 기반으로 동작한다. 반면 목표 기반 에이전트는 목표 달성을 위한 계획과 추론 기능을 수행하며, 내비게이션 시스템이나 산업용 로봇 등에 활용된다. 또한 학습형 에이전트는 환경과의 상호작용을 통해 스스로 성능을 개선하며 추천 시스템이나 사용자 맞춤형 콘텐츠 추천 등에 적용되고 있다. 최근 가장 주목받고 있는 분야는 생성형 에이전트다. 생성형 에이전트는 GPT 계열의 LLM을 기반으로 자연어 이해, 계획 수립, 정보 탐색, 외부 API 호출 등을 통합적으로 수행할 수 있으며, Auto-GPT와 같은 사례는 이러한 가능성을 보여준 대표적 사례로 평가된다. 최근 기술 관점에서 가장 주목되는 변화는 AI 에이전트가 단일 모델 중심에서 '에이전트 생태계(agent ecosystem)' 중심으로 발전하고 있다는 점이다. 과거에는 하나의 AI 모델이 질문과 응답을 처리하는 방식이 주를 이뤘다면, 현재는 여러 전문 에이전트가 역할을 분담하는 멀티 에이전트 구조(Multi-Agent system)가 빠르게 확산되고 있다. 예를 들어 하나의 에이전트는 정보 검색을 담당하고, 다른 에이전트는 일정 관리, 코드 생성, 데이터 분석 등을 수행하는 방식이다. 이러한 구조는 복잡한 업무를 병렬적으로 처리할 수 있도록 하며, 기업형 AI 운영의 핵심 아키텍처로 부상하고 있다. 실제로 OpenAI의 'Operator', Google의 'Project Astra', Anthropic의 'Computer Use' 기능 등은 AI가 단순 대화형 시스템을 넘어 실제 컴퓨터 환경을 이해하고 조작하는 방향으로 발전하고 있음을 보여준다. 이러한 AI 에이전트의 발전은 단순한 기술 향상을 넘어, AI 패러다임 자체의 변화와 맞물려 진행되고 있다. 초기 AI는 규칙 기반 전문가 시스템 중심으로 발전했으며, 정해진 조건에 따라 제한된 작업을 수행하는 수준에 머물렀다. 그러나 2000년대 들어 강화학습 기술이 발전하면서 AI는 스스로 경험을 축적하고 학습할 수 있는 방향으로 진화하기 시작했다. 2016년 등장한 알파고는 목표 기반 추론과 경험 학습을 결합한 대표적 사례로 평가되며, AI 에이전트 발전의 중요한 전환점이 되었다. 이후 GPT-4와 같은 초거대 언어모델이 등장하면서 AI 에이전트는 단순한 질의응답을 넘어 추론·생성·실행 기능을 통합적으로 수행하는 방향으로 발전하고 있다. 최근에는 생성형 AI에 메모리(memory), 장기 계획(planning), 도구 사용(tool use), 외부 API 연동 기능까지 결합되면서, 인간의 업무 흐름 전반을 지원하는 수준으로 고도화되고 있다. 이러한 변화는 실제 기업 환경에서도 빠르게 확산되고 있다. 마이크로소프트는 코파일럿 스튜디오를 통해 기업 맞춤형 워크플로 에이전트 구축을 지원하고 있으며, 세일즈포스는 에이전트포스(AgentForce) 기반 고객지원 자동화를 확대하고 있다. 국내에서도 LG전자의 '챗엑사원(ChatEXAONE)', SK텔레콤의 '에스터(Aster)' 등 다양한 AI 비서 서비스가 등장하며 업무 혁신이 본격화되고 있다. 특히 최근에는 단순 질의응답을 넘어 문서 작성, 회의 요약, 코드 생성, 데이터 분석, 의사결정 지원 등 실제 업무 프로세스를 자동화하는 방향으로 활용 범위가 빠르게 확대되고 있다. 기술적으로 AI 에이전트는 일반적으로 '지각–추론–행동–피드백' 구조를 기반으로 작동한다. 최근에는 여기에 메모리 계층(memory layer), 벡터 데이터베이스(Vector DB), 검색증강생성(RAG), 오케스트레이션 프레임워크 등이 추가되면서 더욱 정교한 형태로 발전하고 있다. 특히 LangChain, AutoGen, CrewAI, Semantic Kernel과 같은 프레임워크는 복수의 에이전트 간 협업과 외부 시스템 연동을 지원하는 핵심 기술로 활용되고 있다. 또한 MCP(Model Context Protocol)와 같은 표준화 논의도 확대되면서, 다양한 AI 도구와 서비스 간 상호운용성이 차세대 AI 생태계의 핵심 과제로 부상하고 있다. 그러나 AI 에이전트의 확산은 새로운 가능성을 열어주는 동시에 다양한 도전 과제도 함께 제기하고 있다. 특히 에이전트의 자율성과 활용 범위가 확대될수록 개인정보 유출, 허위정보 생성, 보안 위협, 오작동 위험과 같은 문제들도 점차 커지고 있다. 실제로 일부 자율형 AI가 악성 명령을 수행하거나 비정상적인 목표를 생성한 사례들이 보고되면서, 인간의 개입과 감독을 전제로 하는 'Human-in-the-loop' 기반 안전 통제 체계의 중요성이 더욱 커지고 있다. 또한 AI가 의사결정 과정에 깊이 관여하게 되면서 설명가능성(XAI), 책임성(Accountability), 윤리적 통제 체계 구축 역시 핵심 과제로 부상하고 있다. 이는 AI 에이전트가 단순한 기술 도구를 넘어 사회·제도적 신뢰 체계와 함께 논의되어야 하는 단계에 진입했음을 의미한다. 이와 동시에 AI 에이전트의 기술적 진화 방향도 빠르게 변화하고 있다. 최근에는 기존의 클라우드 중심 구조를 넘어 온디바이스 AI와 결합되는 흐름이 본격화되고 있다. Qualcomm, Apple, 삼성전자 등 주요 기업들은 스마트폰과 PC 내부에서 직접 실행 가능한 경량 AI 에이전트 기술을 강화하고 있으며, 이는 개인정보 보호와 실시간 처리 측면에서 중요한 변화로 평가된다. 또한 NVIDIA의 'AI 팩토리(AI Factory)' 전략처럼 AI 에이전트 운영을 위한 GPU·데이터센터 인프라 경쟁도 본격화되면서, AI 경쟁의 중심이 모델 자체를 넘어 인프라와 운영 생태계 전반으로 확대되고 있다. 결국 AI 에이전트는 단순한 자동화 기술을 넘어, 스스로 판단하고 실행하며 디지털 노동(digital labor)을 수행하는 새로운 지능형 시스템으로 발전하고 있다. 앞으로 AI 에이전트의 경쟁력은 단순한 모델 성능보다도 멀티 에이전트 협업 구조, 실시간 데이터 연동, 안전성과 설명가능성, 그리고 다양한 시스템 간 상호운용성을 얼마나 효과적으로 구현하느냐에 의해 좌우될 가능성이 크다. 이는 AI 기술 경쟁의 중심이 단순한 모델 개발을 넘어, 다양한 에이전트가 실제 환경 속에서 유기적으로 협업하고 자율적으로 실행되는 '에이전트 생태계' 구축 역량으로 빠르게 이동하고 있음을 의미한다.