[안광섭의 AI 진테제] 메모리 주식 흔든 구글 '터보퀀트'
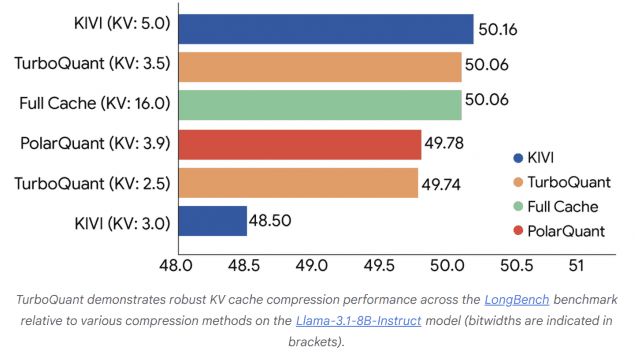
지난 수요일 미국 증시에서 흥미로운 장면이 연출됐다. 나스닥 100이 상승하는 와중에 메모리 반도체 주식만 역행했다. 샌디스크 -5.7%, 웨스턴 디지털 -4.7%, 씨게이트 -4%, 마이크론 -3%. 방아쇠를 당긴 건 구글 리서치가 공개한 터보퀀트(TurboQuant)라는 압축 알고리즘이다. 'AI가 메모리를 덜 쓰게 해주는 기술'이라는 헤드라인만 보면 메모리 업체들에게 악재처럼 보인다. 그런데 이 기술이 실제로 줄이는 것은 GPU 위의 임시 기억 공간이지, 서버에 꽂히는 HBM(High Bandwidth Memory)이나 DRAM 모듈이 아니다. 시장이 읽은 신호와 기술이 말하는 신호 사이에 간극이 있고, 그 간극 너머에는 AI 하드웨어 전체에 걸친 더 큰 질문이 놓여 있다. 터보퀀트가 실제로 하는 일 AI가 대화를 이어갈 때, 앞에서 한 말을 기억하려면 KV 캐시(Key-Value Cache)라는 임시 메모리에 정보를 저장해야 한다. 대화가 길어질수록 이 메모리는 기하급수적으로 늘어나고, AI 서비스 비용을 끌어올리는 주범 중 하나다. '터보퀀트'는 이 임시 기억을 최대한 작게 압축하면서도 내용을 거의 그대로 유지하는 알고리즘이다. 추가 학습이나 파인튜닝(fine-tuning, 특정 분야 추가 학습)이 필요 없다. 핵심은 2단계 구조다. 1단계인 폴라퀀트(PolarQuant)는 데이터에 무작위 회전을 적용해 값들의 분포를 균일하게 만든다. 크기가 제각각인 짐을 한번 뒤섞어 비슷한 규격으로 정리하는 것과 비슷하다. 이렇게 하면 동일한 상자에 효율적으로 담을 수 있다. 2단계인 QJL(양자화된 존슨-린덴스트라우스)은 1차 압축 이후 남은 잔여 오차를 단 1비트로 한 번 더 보정한다. 논문에 따르면, 이 2단계 접근법 덕분에 3.5비트에서 원래 모델과 사실상 동일한 품질을 유지하고, 10만 4천 토큰 길이의 테스트에서도 100% 정확도를 보였다. 압축률은 4.5배 이상이다. 다만 짚어야 할 대목이 있다. 구글 블로그에서 강조한 '최대 8배 속도 향상'은 어텐션 로짓 연산이라는 특정 단계에서의 수치다. 전체 추론 처리량의 8배가 아니다. '6배 메모리 축소'도 블로그와 논문 사이에 미세한 차이가 있다. 논문은 좀 더 보수적으로 '4.5배 이상'이라고 표현한다. 수치가 발표 채널에 따라 다르게 포장되는 것은 기술 뉴스를 읽을 때 늘 주의해야 할 부분이다. 시장의 논리, 그리고 그 한계 시장의 추론은 단순했다. AI가 메모리를 6분의 1만 써도 된다면 메모리 수요가 줄어드는 것 아닌가? 올해 메모리 주식들이 워낙 많이 올랐기 때문에 차익 실현의 구실이 필요했던 측면도 있다. 그러나 한 발짝 뒤로 물러서면, KV 캐시와 HBM은 같은 '메모리'라는 단어를 쓰지만 작동하는 층위가 다르다는 점이 보인다. KV 캐시는 LLM(대규모 언어 모델)이 대화 중 이전 계산을 저장하는 GPU 위의 임시 공간이다. 반면 HBM 수요는 모델의 훈련과 추론 전체에 걸친 대역폭 병목에서 발생한다. 트렌드포스(TrendForce)에 따르면 2026년 HBM 수요는 전년 대비 70% 이상 증가할 전망이고, 뱅크오브아메리카(BofA)는 올해 HBM 시장 규모를 약 546억 달러(전년 대비 58% 성장)로 추정한다. SK하이닉스, 삼성, 마이크론 모두 2026년 HBM 물량은 사실상 완판 상태라고 밝히고 있다. 비유하자면 이렇다. '터보퀀트'는 사무실 책상 위의 메모 정리법을 개선한 것이고, HBM 수요는 건물 자체에 더 많은 사무실이 필요한 것이다. 메모 정리가 잘 된다고 건물 수요가 줄지는 않는다. 오히려 한 사무실에서 더 많은 일을 처리할 수 있으니 건물을 더 짓고 싶어질 수도 있다. 건설에서 최적화로, 국면 전환 신호 필자가 '터보퀀트' 자체보다 더 흥미롭게 보는 것은 이 뉴스에 시장이 반응한 방식이다. 메모리 주식만의 이야기가 아니기 때문이다. 좀 더 넓게 보면 지금 AI 하드웨어 스택 전체가 같은 질문을 받고 있다. 엔비디아는 2026 회계연도에 매출 2159억 달러, 순이익률 약 56%라는 전례 없는 실적을 기록했지만, 주가는 지난해 10월 고점 대비 약 15% 낮은 수준에서 움직이고 있다. 마이크론도 이틀 전 역대 최고 분기 실적(매출 238억6000만 달러, 매출총이익률 74.4%)을 발표했지만, 시장의 관심은 "250억 달러 이상의 설비투자를 감당할 수 있느냐"에 쏠렸다. GPU도 빠지고, DRAM도 빠지고, NAND 스토리지도 빠지고 있다. 시장이 묻고 있는 진짜 질문은 "이 속도의 인프라 투자가 지속 가능한가?"다. 마이크로소프트, 메타, 알파벳, 아마존 4사의 2026년 설비투자 가이던스 합산이 약 6500억 달러에 달한다. 인류 역사에서 단일 목적에 투입된 민간 자본 중 가장 큰 규모에 속한다. GTM(Go-To-Market) 전략 관점에서 보면, 모든 기술 인프라 사이클에는 '건설 국면'과 '최적화 국면'이 있다. 건설 국면에서는 "일단 깔아라"가 전략이다. 최적화 국면에서는 "깔아놓은 것의 효율을 어떻게 극대화할 것인가"가 전략이 된다. 터보퀀트, 엔비디아가 같은 'ICLR 2026(International Conference on Learning Representations, 4월 23일 ~ 4월 27일)'에서 발표할 KVTC(KV Cache Transform Coding, 최대 20배 압축), 하이퍼스케일러들의 자체 칩 개발, 이 모든 움직임은 최적화 국면의 신호다. 그렇다고 이것이 약세 신호인가. 필자는 아니라고 본다. 최적화 국면은 성장의 끝이 아니라 성장이 성숙해지는 과정이다. 다만 시장이 가격에 반영하는 방식이 달라질 뿐이다. 건설 국면에서는 "다 사라"였다면, 최적화 국면에서는 누가 이 효율화의 수혜자이고 누가 비용을 부담하는가를 가려야 한다. 핵심은 시간 축 구분 '터보퀀트' 같은 소프트웨어 최적화가 하드웨어 수요 증가 속도에 영향을 줄 수 있는 것은 2027년 이후의 이야기다. 2026년의 메모리 공급 부족은 물리적인 팹 건설과 수율의 문제이고, 알고리즘으로 해결되는 영역이 아니다. 시장이 이 두 가지 시간 축을 혼동할 때, 그것이 곧 기회이기도 하고 리스크이기도 하다. 터보퀀트 원본 논문(https://arxiv.org/abs/2504.19874)은 2025년 4월 28일에 공개됐다. 약 1년 전 제안된 기술이 학회 발표를 앞두고 재조명되면서 시장을 흔든 것이다. 기술 자체는 새롭지 않았지만, 시장이 읽는 타이밍은 달랐다. 정리하면 이렇다. 터보퀀트는 AI 추론 효율을 한 단계 끌어올리는 의미 있는 기술이다. 그러나 메모리 주식이 빠진 이유는 이 기술 하나가 아니라, AI 하드웨어 스택 전반에 걸친 '건설에서 최적화로'의 국면 전환 신호를 시장이 읽기 시작했기 때문이다. 기술 층위를 이해하고 시간 축을 구분할 수 있다면, 변동성 속에서 더 나은 판단을 내릴 수 있다. 지금 필요한 것은 공포도 낙관도 아닌, 어떤 메모리가 줄고 어떤 메모리가 느는지를 가려내는 눈이다. ■ 필자 안광섭은... 세종대학교 경영학과 교수이자 OBF(Oswarld Boutique Consulting Firm) 리드 컨설턴트다. 대학에서 경영데이터 관리, 비즈니스 애널리틱스 등 데이터 분석을 가르치는 한편, 현장에서는 GTM 전략과 인공지능 전략 컨설팅을 이끌며 기술과 비즈니스의 접점을 설계하고 있다. AI 대화 시스템의 기억 아키텍처(HEMA) 연구로 학술 논문을 발표했으며, 매일 글로벌 AI 논문을 큐레이션하는 Daily Arxiv 프로젝트를 운영하고 있다. 고려대학교 KBMA 기술경영전문대 석사과정을 졸업했다. 저술한 책으로 '생각을 맡기는 사람들: 호모 브레인리스'가 있다.