세계 첫 AI기본법 시행한 한국…외신 평가는?
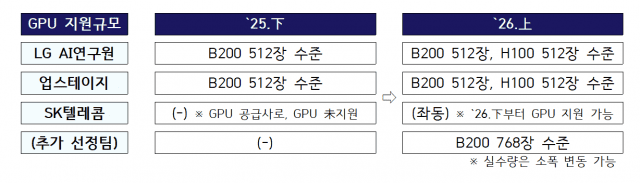
한국 정부가 지난 22일 인공지능(AI)기본법을 시행한 가운데 외신들은 엇갈린 반응을 내놓고 있다. 이번 법안이 AI 산업 진흥 기틀을 마련했다는 평가가 등장한 반면 인프라 규제에 대한 책임은 회피했다는 시각도 공존하고 있다. 23일 외신은 한국 AI기본법을 미국과 유럽연합(EU), 일본 등 각국 내 AI 정책과 비교·분석하며 이런 평가를 한 것으로 나타났다. 로이터통신과 AFP는 한국이 AI법을 시행한 첫 국가라는 점을 중점적으로 보도했다. 두 매체는 딥페이크·허위정보 대응 조항과 고영향 AI에 대한 인간 감독 원칙 명시를 통해 안전과 신뢰 확보에 방점을 찍었다고 분석했다. 일부 외신은 규제 부담에 대한 우려 목소리를 내기도 했다. 일부 외신은 규제 리스크가 혁신 속도를 저해할 가능성을 짚었다. 특히 AI 스타트업 비용 부담을 문제로 지적했다. 타임스오브인디아는 "스타트업들이 법 조항 모호성과 시행 준비 부족으로 불안감을 표출하고 있다"며 "일부 기업은 법 준수를 위해 외부 법률 자문을 받는 등 추가 비용을 감수해야 할 수 있다"며 "정식 준수 계획을 마련한 스타트업도 극소수"라고 보도했다. EU·미국 상황과 비교·분석…"일본, AI 표시 의무 없어" 언급 아시아·태평양(APAC) 지역 언론은 한국 AI기본법을 'EU AI 액트'와 비교 분석했다. 이들은 고위험 AI 정의 방식과 딥페이크 대응 방식에서 두 법 차이점을 짚었다. 싱가포르 매체 스트레이츠 타임스는 한국 AI기본법과 EU AI 액트 핵심 차이를 '고위험 AI' 개념 설정에서 찾았다. 해당 매체는 EU가 의료·채용·법 집행 등 활용 분야 위험도 기준으로 규제 대상을 정하는 반면 한국은 누적 학습 연산량 등 기술적 임곗값(threshold)으로 고성능 AI를 구분한다는 점을 설명했다. 스트레이츠 타임스는 "한국 안전 요건은 극히 제한적인 일부 첨단 모델에만 적용될 것"이라며 "실제 한국 정부는 국내외 막론하고 현재 어떤 AI 모델도 해당 규제 기준을 충족하지 않는다는 입장"이라고 언급했다. 이어 "EU는 수년에 걸친 전환 기간을 두고 단계적으로 규제를 시행 중"이라고 덧붙였다. 일본 IT 매체 기즈모도 재팬은 한국 딥페이크 대응 방안을 소개했다. 해당 매체는 한국 AI기본법을 AI 생성물 출처를 이용자가 명확히 인식하도록 만드는 제도적 장치로 규정했다. 기술 자체를 억제하기보다 표시·고지 중심으로 신뢰 문제에 접근했다고 봤다. 특히 이미지·텍스트·음성 등 사람이 만든 것과 구분하기 어려운 콘텐츠에 표시 의무를 부과한 조항을 핵심으로 짚었다. 규제 초점을 기술 통제보다 이용자 판단권과 정보 선택권 보호에 둔 신호로 해석했다. 기즈모도 재팬은 "딥페이크 전면 규제에 가까운 EU와 달리 한국은 고지·표시를 중심으로 한 단계적 대응을 선택했다"고 봤다. 이어 "일본에는 아직 유사한 법적 표시 의무가 없다"고 덧붙였다. "한국 AI기본법, 에너지·환경 이슈 빠져" 미국 언론은 한국이 AI 인프라 확산에 따른 에너지·환경 부담을 직접적으로 다루지 않았다는 점을 지적했다. AI 수요 증가로 데이터센터와 전력 사용이 급증하는 상황에서 자원 관리 방안이 법에서 빠졌다는 평가다. 미국 에너지 전문매체 E플러스E리더는 "한국은 AI 시스템 에너지 소비나 효율 기준, 전력망 용량과 계통 연계 요건, 데이터센터 냉각을 위한 물 사용, AI 인프라와 연계된 온실가스 배출, 기후 리스크 등을 포괄적으로 규율하지 않았다"고 지적했다. 그러면서 "AI 데이터센터 개발을 장려하는 정책 기조와 달리 환경·에너지 요소는 제도적으로 분리됐다"고 진단했다. 해당 매체는 이런 접근 방식이 미국의 AI 규제 방식과 유사하다고 짚었다. 실제 미국은 에너지 사용이나 환경 영향을 규율하는 연방 차원 AI 법을 내지 않은 상태다. 다만 AI로 인한 전력·환경 문제를 데이터센터 인허가, 전력 유틸리티 규제, 환경 관련 법·규정 등 인프라 관리 체계에서 사후적으로 다룬다. E플러스리더는 "한국은 에너지와 환경 문제를 기존 인프라·환경 정책 영역에 맡기는 분업형 규제 구조를 택했다"고 해석했다. 이어 "AI 인프라 규모가 빠르게 커질수록 향후 에너지·기후 이슈를 법·제도적으로 어떻게 연결할지가 새로운 과제로 떠오를 것"이라고 전망했다.