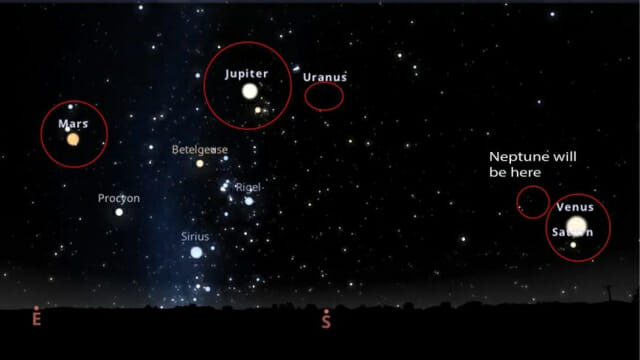
[포토] 달 옆에 줄 선 태양계 행성들…멋진 '행성 퍼레이드' 장면
프랑스 천체사진작가 그웨나엘 블랑크(Gwenaël Blanck)가 달 옆에 줄을 선 태양계 행성들을 촬영하는 데 성공했다고 과학전문매체 라이브사이언스가 12일(이하 현지시간) 보도했다. 지난 달 중순부터 태양계 행성들이 줄지어 밤하늘에 떠오르는 천문 현상인 '행성 정렬'이 계속되고 있다. 이 현상은 '행성 퍼레이드'로 불리며 우리나라를 포함해 전 세계에서 관측할 수 있다. 공개된 사진을 보면 달 옆에 금성, 화성, 목성, 토성, 천왕성, 해왕성이 차례대로 줄 지어 있는 모습을 확인할 수 있다. 이미지 속 천체들은 밤하늘에 흩어져 있었으나, 그웨나엘 블랑크는 지난 2일 밤 파리에서 촬영한 달과 각각의 행성 사진을 편집해 특별한 사진을 완성시켰다. 그는 이번 달 초에도 파리 에펠탑 위로 금성과 달이 나란히 서 있는 멋진 장면을 공개해 화제가 되기도 했다. 그는 오후 6시 30분~오후 7시 50분 사이 망원경에 부착된 디지털 카메라를 사용해 천체 사진을 찍은 후 달 옆에 6개 행성을 직선으로 배치해 합성 사진을 만들었다. 그는 “달, 천왕성, 목성, 화성은 하늘 더 높은 곳에 있어서 촬영하기 더 쉬웠다"며 "유일하게 없는 행성은 수성인데, 이 달 말과 3월 초에 볼 수 있게 될 것"이라고 밝혔다. 이 놀라운 행성 퍼레이드에 2월 말에서 3월 초 수성이 가세하며, 태양계 행성 중 7개 행성이 직선으로 정렬하는 이벤트가 일어날 예정이다. 이번 기회를 놓치면 이와 비슷한 행성 정렬 현상은 2028년 10월까지 기다려야 하며, 금성, 화성과 목성, 토성 등 5개 행성 정렬 현상은 오는 2040년에야 볼 수 있는 것으로 알려져 있다.