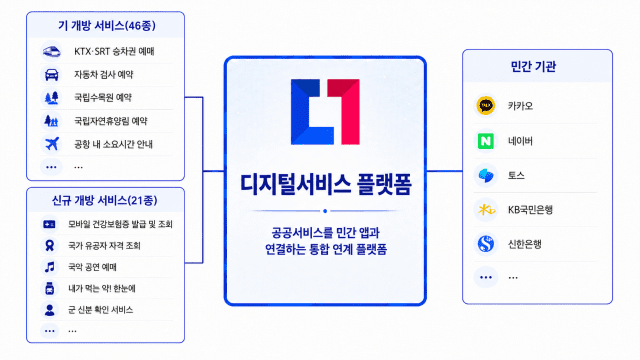
공무원이 직접 개발하는 AI 행정서비스…'AI 정부 실험실' 시범 운영
행정안전부가 공무원이 직접 인공지능(AI)을 활용해 행정 업무를 개선할 수 있는 'AI 정부 실험실'을 가동한다. 반복 업무를 줄이고 현장 중심의 행정혁신을 확산하기 위한 기반으로 개발 결과물은 범정부 차원의 공공 저장소를 통해 공유된다. 행정안전부는 공무원이 AI 코딩과 AI 에이전트 기술을 활용해 업무 과정의 비효율을 스스로 해결할 수 있도록 지원하는 'AI 정부 실험실'을 단계적으로 구축·운영한다고 2일 밝혔다. AI 정부 실험실은 현장 공무원이 업무 수행 과정에서 발견한 문제를 AI 기술로 직접 해결하고, 신속하게 시제품을 제작·검증할 수 있도록 지원하는 공공부문 AI 전환(AX) 플랫폼이다. 그동안 공공 정보화 사업은 예산 확보와 기획, 구축, 운영 등 복잡한 절차를 거치면서 실제 업무 현장의 개선 요구를 즉시 반영하기 어려웠다. 이 때문에 단순 반복 업무나 수작업 중심의 비효율이 장기간 지속되는 사례도 적지 않았다. 행안부는 이러한 문제를 해소하기 위해 우선 인터넷망 기반의 AI 정부 실험실을 7월 3일부터 시범 운영한다. 시범 단계에서는 민간 클라우드와 AI 개발 도구, 개방형 데이터, 오픈 API 등을 활용할 수 있는 환경을 제공한다. 이를 통해 공무원들은 별도의 예산이나 전문 개발 조직 없이도 업무 자동화 프로그램이나 AI 기반 업무지원 도구를 직접 개발하고 성능을 검증할 수 있게 된다. 행안부는 개발 결과물이 개인 PC나 개별 저장소에 머무르지 않도록 '공공 개발산출물 저장소(공공 깃랩)'도 함께 구축한다. 저장소에는 과제 문서와 소스코드, 프롬프트 등 개발 과정에서 생성된 산출물이 체계적으로 등록·관리된다. 이를 통해 특정 기관의 업무혁신 사례를 다른 중앙부처나 지방자치단체에서도 활용할 수 있도록 하고, 우수 사례의 재사용과 확산을 촉진한다는 계획이다. 또한 정기적으로 우수 사례를 선정해 포상하는 등 적극적으로 참여한 공무원에게 실질적인 인센티브도 제공할 예정이다. 제도적 기반 마련에도 나선다. 행안부는 '공공 AX 업무 지침'(가칭)을 마련해 AI 활용 및 개발 과정에서 필요한 기준과 절차를 정립한다. 해당 지침에는 과제 발굴, 개발 환경 이용, 보안 준수, 품질 검증, 산출물 등록 및 확산 절차 등이 포함될 예정이다. 행안부는 내년부터 정부 내부 업무망 환경으로 AI 정부 실험실을 확대할 계획이다. 업무망 환경이 구축되면 내부 행정 데이터와 법령, 지침, 민원 사례 등을 활용해 보다 고도화된 AI 서비스와 업무 전용 AI 에이전트 개발이 가능해질 전망이다. 이와 함께 공공부문 AI 혁신 과제를 통합 관리하는 '공공 AX 포털'도 구축한다. 해당 포털은 국민과 공무원의 아이디어 제안부터 과제 발굴, 전문가 검토, 우수사례 선정, 기관 간 확산까지 전 과정을 관리하는 플랫폼 역할을 수행하게 된다. 행안부는 이를 통해 현장에서 검증된 혁신 모델을 범정부 차원에서 체계적으로 공유하고, 공공 AI 전환의 확산 속도를 높인다는 방침이다. 윤호중 행정안전부 장관은 "공공 AI 전환의 핵심은 현장의 문제를 가장 잘 이해하는 공무원이 AI를 활용해 직접 해결책을 만들어내는 데 있다"며 "모든 공무원이 AI를 업무 파트너처럼 활용하고 국민이 행정서비스의 변화를 체감할 수 있도록 공공 AX 기반을 지속적으로 확대해 나가겠다"고 말했다.