잠만 자도 질병 예측 가능…스탠퍼드 AI, 하룻밤 수면으로 130가지 병 찾아낸다
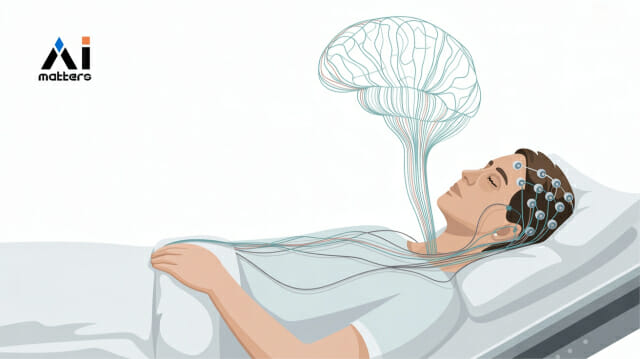
미국 스탠퍼드 대학 연구팀이 단 하룻밤 잠을 자는 동안의 데이터만으로 향후 걸릴 수 있는 질병을 예측하는 인공지능 'SleepFM'을 개발했다. 해당 연구 논문에 따르면, 이 AI는 약 6만 5,000명이 자는 동안 측정한 58만 5,000시간 이상의 데이터로 학습했으며, 사망 위험, 치매, 심근경색 등 130가지 질병을 75% 이상의 정확도로 예측할 수 있다. 의학 분야 최고 권위 학술지 '네이처 메디슨'에 실린 이 연구는 수면이 단순히 쉬는 시간이 아니라 우리 몸의 건강 상태를 보여주는 중요한 신호임을 입증했다. 잠자는 동안 뇌파·심장박동·호흡 모두 분석 SleepFM은 병원에서 하는 '수면다원검사'라는 정밀 검사 데이터를 활용한다. 수면다원검사는 잠자는 동안 머리에 센서를 붙여 뇌파를 측정하고, 가슴에 전극을 붙여 심장박동을 기록하며, 코와 입 주변에 센서를 달아 호흡 패턴을 관찰하는 검사다. 근육 움직임도 함께 측정한다. 연구팀은 스탠퍼드 수면 클리닉, 바이오세레니티, 다민족죽상동맥경화증 연구, 남성 노인 수면장애 결과 연구 등 4곳에서 모은 데이터를 사용했다. 스탠퍼드 수면 클리닉에서만 3만 5,052명의 데이터가 모였고, 나머지 기관들도 수천 명씩 데이터를 제공했다. 이는 기존 수면 분석 AI가 사용한 데이터(2,500~1만 5,913건)보다 훨씬 많은 양이다. 중요한 점은 병원마다 검사 방식이 조금씩 다르다는 것이다. 어떤 병원은 뇌파를 6군데에서 측정하고, 다른 병원은 10군데에서 측정한다. 이런 차이를 AI가 자동으로 처리할 수 있도록 '채널 독립적;설계'를 적용했다. 마치 여러 나라 언어를 동시에 이해하는 번역기처럼, 서로 다른 형태의 검사 데이터를 모두 이해할 수 있다. 6년 후 걸릴 병까지 미리 알아낸다 연구팀은 스탠퍼드 수면 클리닉에서 검사받은 환자들의 병원 진료 기록을 추적했다. 환자가 검사 후 어떤 병에 걸렸는지, 언제 진단받았는지를 확인한 것이다. 총 1,041개 질병을 분석했고, 그중 130개 질병에서 정확도 75% 이상을 달성했다. 특히 눈에 띄는 것은 사망 위험 예측이다. 환자가 향후 사망할 가능성을 84%의 정확도로 맞췄다. 치매는 85%, 심근경색은 81%, 심부전은 80% 정확도를 보였다. 이 수치는 '콘코던스 지수'라는 측정 방식으로 계산했는데, 100명 중 84명의 위험도 순서를 정확하게 맞춘다는 뜻이다. 연구팀은 6년이라는 기간을 기준으로 삼았다. 예를 들어 2020년에 수면 검사를 받은 사람이 2026년까지 심장병에 걸렸다면 AI의 예측이 맞은 것으로 본다. 1년 후부터 6년 후까지 다양한 기간으로 테스트했는데, 대체로 비슷한 정확도를 유지했다. 질병 종류도 다양하다. 암 중에서는 전립선암(90%), 유방암(90%), 피부암(83%)을 잘 예측했다. 뇌 관련 질환에서는 파킨슨병을 93% 정확도로 찾아냈다. 심혈관 질환에서는 고혈압성 심장병(88%), 뇌출혈(82%)의 위험을 정확하게 예측했다. 다른 병원 데이터로도 정확하게 작동 AI 모델이 실제로 쓰기 위해서는 다른 병원에서도 잘 작동해야 한다. 연구팀은 이를 확인하기 위해 '수면 심장 건강 연구'라는 별도의 데이터로 테스트했다. 이 데이터는 40세 이상 성인 6,441명의 정보를 담고 있으며, 테스트 결과는 인상적이었다. 뇌졸중 예측 정확도 82%, 울혈성 심부전 85%, 심혈관 질환 사망 88%를 기록했다. 이 데이터에는 협심증 환자 704명, 울혈성 심부전 환자 190명, 뇌졸중 환자 95명 등이 포함됐다. 처음 보는 데이터임에도 높은 정확도를 유지한 것이다. 하지만 시간이 지나도 정확할까? 이를 연구하기 위해, 연구팀은 2020년 이후 환자 데이터로도 별도 테스트를 진행했다. AI는 2020년 이전 데이터로만 학습했기 때문에 최신 데이터는 처음 보는 셈이다. 그럼에도 사망 위험 83%, 심부전 80%, 치매 83%의 정확도를 유지했다. 이는 의료 환경이 바뀌고 환자 특성이 달라져도 AI가 안정적으로 작동한다는 증거다. 나이·성별만 아는 것보다 훨씬 정확 일반적으로 병원에서는 환자의 나이, 성별, 체중 같은 기본 정보로 질병 위험을 추정한다. 예를 들어 나이가 많으면 암 위험이 높다는 식이다. 연구팀은 이런 방식과 비교하기 위해 나이, 성별, 체질량지수, 인종 정보만으로 예측하는 단순 모델을 만들었다. 결과는 명확했다. SleepFM은 질병 종류에 따라 5~17% 더 정확했다. 특히 뇌 질환에서 차이가 컸다. 노인성 치매의 경우 SleepFM은 정확도 99%를 기록한 반면, 기본 정보만 쓴 모델은 87%에 그쳤다. 근육 신경 장애는 81% 대 42%, 발달 지연은 80% 대 58%로 큰 격차를 보였다. 심혈관 질환에서도 마찬가지다. 동맥경화증은 92% 대 74%, 급성 폐성 심장병은 80% 대 74%였다. 당뇨병 합병증도 87% 대 79%로 SleepFM이 앞섰다. 흥미로운 점은 적은 데이터로도 잘 작동한다는 것이다. 연구팀이 데이터의 10%만으로 SleepFM을 학습시켰더니, 5배 많은 데이터로 학습한 단순 모델보다 오히려 정확했다. 심혈관 질환 사망, 울혈성 심부전, 심근경색, 뇌졸중 등 4개 질환에서 이런 결과가 나왔다. 이는 기본 학습이 잘된 AI는 적은 데이터로도 효율적으로 작동한다는 의미다. 뇌파는 치매, 호흡은 대사 질환 예측에 효과적 연구팀은 어떤 신호가 어떤 질병 예측에 중요한지 세밀하게 분석했다. 뇌파는 정신 질환과 신경 질환을 예측하는 데 가장 효과적이었다. 호흡 패턴은 호흡기 질환과 대사 질환을, 심전도는 심혈관 질환을 잘 예측했다. 수면 단계별로도 차이가 있었다. 얕은 수면(1/2단계)과 꿈꾸는 수면(렘수면)이 심혈관 질환과 뇌 퇴행성 질환 예측에 더 유용했다. 하지만 전체적으로는 모든 신호를 함께 분석할 때 가장 정확했다. 이는 수면이 여러 신체 시스템의 복합적인 상호작용이라는 것을 보여준다. 실제로 연구팀이 각 신호별로 별도의 AI를 만들어 비교했더니, 모든 신호를 결합한 모델이 최고 성능을 냈다. 뇌파만 보거나 심전도만 봐서는 전체 건강 상태를 파악하기 어렵다는 뜻이다. 잠이 미래 건강을 말해주는 이유 왜 수면만으로 이렇게 많은 질병을 예측할 수 있을까? 연구팀은 수면 문제가 많은 질병의 초기 신호라고 설명한다. 실제로 정신 질환, 뇌 퇴행성 질환, 심혈관 질환 등은 본격적인 증상이 나타나기 전에 수면 장애가 먼저 발생하는 경우가 많다. 알츠하이머병의 경우 초기에 깊은 수면이 줄어들고, 꿈꾸는 수면에 문제가 생기며, 특정 뇌파 활동이 감소한다. SleepFM은 이런 패턴을 정확도 91%로 포착했다. 파킨슨병은 종종 꿈꾸는 수면 중 이상 행동이 먼저 나타나는데, AI는 이를 89% 정확도로 찾아냈다. 심혈관 질환 예측에서도 수면 데이터가 유용했다. 10년 후 심혈관 질환 사망 위험을 88% 정확도로 예측했는데, 이는 이전 연구(84%)보다 높은 수치다. 심방세동은 81% 정확도를 기록했다. 연구팀의 분석에 따르면 심전도와 호흡 신호가 함께 작용해 심혈관 질환을 예측하는 것으로 나타났다. 수면 무호흡과 심장 활동 정보가 통합되는 것이다. FAQ (※ 이 FAQ는 본지가 리포트를 참고해 자체 작성한 내용입니다.) Q1. 일반인도 이 검사를 받을 수 있나요? A. 이 연구는 병원에서 시행하는 수면다원검사 데이터를 활용했습니다. 수면다원검사는 수면 장애가 의심될 때 병원에서 받을 수 있는 검사로, 하룻밤 병원에 입원해 여러 센서를 몸에 부착하고 잠을 잡니다. 현재 SleepFM은 연구 단계이며, 실제 임상에서 사용되려면 추가 검증이 필요합니다. Q2. 웨어러블 기기로도 이런 예측이 가능한가요? A. 이 연구는 병원급 정밀 장비로 측정한 뇌파, 심전도, 근전도, 호흡 신호를 모두 사용했습니다. 현재 시중의 웨어러블 기기는 심박수나 움직임 정도만 측정하므로 동일한 수준의 예측은 어렵습니다. 다만 연구팀은 웨어러블 수면 기술이 발전하면 향후 이런 모델이 실시간 건강 모니터링에 활용될 가능성을 언급했습니다. Q3. 왜 수면만으로 이렇게 많은 질병을 예측할 수 있나요? A. 수면은 뇌, 심장, 호흡, 근육 등 여러 신체 시스템이 동시에 작용하는 복잡한 과정입니다. 많은 질병들이 본격적인 증상을 보이기 전에 수면 패턴에 먼저 영향을 미칩니다. 예를 들어 알츠하이머병은 초기에 깊은 수면과 특정 뇌파가 감소하고, 파킨슨병은 꿈꾸는 수면 중 이상 행동이 나타나며, 심혈관 질환은 호흡 패턴과 심박수에 변화를 일으킵니다. SleepFM은 이런 미세한 패턴을 포착해 미래 질병 위험을 예측합니다. ■ 이 기사는 AI 전문 매체 'AI 매터스'와 제휴를 통해 제공됩니다. 기사는 클로드 3.5 소네트와 챗GPT를 활용해 작성되었습니다. (☞ 기사 원문 바로가기)