[박희범의 과학카페] 출연연 휴머노이드 데이터 공개 '천리길'…그래도 한걸음씩 가야
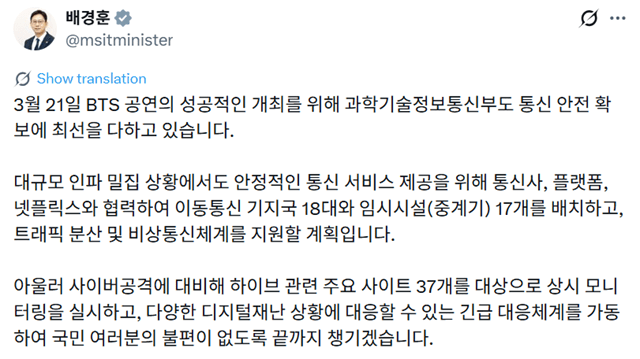
과학기술정보통신부가 휴머노이드 개발을 가속화하기 위한 전초전을 시작했다. 출연연구기관을 모아 휴머노이드 전략 협의체를 발족한 것. 목표는 서로가 맞물려 있는 데이터 등 오픈 플랫폼 구조 확보와 기술 개발 속도 등 2개다. 휴머노이드 개발은 미국 제네시스 미션에 대응한 K-문샷 핵심 미션이다. 단순한 기능적 로봇을 뛰어넘는 피지컬 AI의 결정판으로 주목받고 있다. 지난 달 말 대전서 열린 '출연연 휴머노이드 전략 협의체' 1차회의는 로봇과 관련한 기관 7개가 모였다. 출연연에서는 한국기계연구원(KIMM)을 비롯한 한국과학기술연구원(KIST), 한국전자통신연구원(ETRI), 한국생산기술연구원(KITECH), 한국철도기술연구원(KRRI)과 대학에서 KAIST와 GIST가 참여했다. 오프라인만 과기정통부를 포함해 총 28명이 모여 각자 가진 역량을 어떻게 모아 공개할 것인지 머리를 맞댔다. 이날 행사에는 줌기능을 이용한 온라인 참가 기관도 5개나 됐다. GIST는 버스 안에서 접속해 회의에 참가했다. 그만큼 절박하고, 절실하게 다가왔다. 이날 논의 테이블 위에 올라온 사업은 KIMM이 지난해부터 주도중인 총 2,194억 원 규모의 휴머노이드 엔지니어 및 하우스키퍼 개발과 KIST가 최근 공개한 한국형 차세대 휴머노이드를 지향하는 카펙스(KAPEX)와 이의 고도화다. 고도화에만 2026~2030년 485억 원 정도 필요하다. 데이터-바디-지능 역량 한 곳에 모을 방안 강구 이날 협의체 회의 골자는 휴머노이드 개발에서 핵심인 데이터와 바디, 지능 역량을 어떻게 한 곳에 모아 활용할 것인가였다. 이를 모아 궁극적으로 우리나라 기업들이 데이터든 뭐든 쉽게 활용할 오픈 플랫폼을 만들겠다는 것이다. 과기정통부 입장은 "데이터를 공개하는 방안을 찾아달라. 필요한건 다 지원한다"로 집약됐다. 회의 서두는 운경숙 기초원천연구정책관이 풀었다. "협의체는 브레인과 바디, 데이터 등 3대 핵심 분과로 운영한다. 모두가 원팀이 돼야 한다. 과기정통부도 여러 부서가 참여하고 2차관실에서도 협력한다. 나아가 부처간 협력도 할 것이다. 산업부는 제조현장 확산을 담당할 것이고, 우리 부는 데이터 결집 등을 맡아 연계한다. 산업체 협력은 말할 것도 없다. 중요한 부분이 각자 연구개발을 진행하는 등 최대한 존중할 것이지만, 데이터는 하나로 결집되야 한다. 데이터 활용을 어덯게 하느냐에 따라 이 협의체 성패가 좌우된다. 기관이 보유한 데이터를 최대한 개방하고 공유한다는 점을 특별히 유념해 달라. 데이터 공개를 위한 추가 예산 확보 등은 얘기해달라. 4월 1일부터 예산작업하니 적극 제안해달라." 윤 정책관은 협의체를 만든 취지에 대해선 이렇게 설명했다. "휴머노이드도 미국이나 중국이 글로벌 주도권 다툼을 시작했다. 우리도 총력을 다해야 한다. 좋은 결과를 내려면, 각자 분산형 연구로는 모자란 부분이 생긴다. 그건 모두가 동의하는 부분이다. 분산 연구에 따른 중복 투자나 연구단절을 방지하고 역량을 결집하기 위해 협의체를 만들었다." "분산연구 단점 해소 차원서라도 협업 절실하지만…" 그러나 이날 논의에 참가한 출연연구기관 입장은 대체로 어떻게 할 것인지를 논의하기 보다는 "이런 저런 점이 어렵다"는 쪽에 맞춰졌다. 어려운 이유에 대해 ▲기술 개발 공정 상 데이터를 당장 확보하는 것의 어려움 ▲데이터 포맷이나 정의, 표준 규약 등 서로 안맞거나 다른 부분에 대한 정리의 필요성 ▲데이터가 아무리 작은 작업도 테라급인데 이를 위한 컴퓨팅 파워 선결과제 ▲GPU 확보 ▲데이터 수집도 중요하지만, 검수 인력이 전체의 30~40% 필요한데, 이에 대한 대비 및 확보여부 ▲참여기관, 특히 기업 입장서는 데이터가 자산이고 경쟁력이라는 점 ▲데이터를 사고 판다는 측면에서 과제의 재정비 필요성 ▲데이터를 모아도 하드웨어가 다르면 소용 없기 때문에 일정기간 과도기 필요 등이 제시됐다. 또 ▲독자 플랫폼 만들자는 것은 말이 안된다 ▲시뮬레이터를 만들어 튜닝하며 협업환경부터 시도 ▲데이터를 마구 뿌리기보다 가이드라인을 정비하고, 수집-정제-가공 샘플 케이스 만들어 피드백부터 하자 ▲개방형 생태계 당장 만드는 것 쉽지 않다. 먼저 챌린지 태스크 디자인을 해보자 ▲하드웨어는 휴머노이드 개념도 없다 ▲이기종 하드웨어에 대한 데이터 활용 전략 수립 필요성▲자존심이 뭐 중요하냐, 남들 것 가져다 쓸 수있는것 쓰고 모자란 걸 채우자 등등 다양한 의견이 개진됐다. 이날 3시 30분부터 진행된 회의 대부분은 데이터 공개에 모아졌다. 가능하면 올해 내 데이터를 공개할 기반을 마련해 달라는 것이 과기정통부 입장이었다. "이렇게 하자, 그게 어렵다면 최소한의 공개 시스템이라도 만들어 시범적으로라도 해보자"는 설득적 입장을 주로 폈다. 논의는 예정시간보다 25분 초과했다. 원팀 논의가 생각보다 어렵고, 할 일도 엄청 많아 보였다. 그런데, KIST와 KIMM은 이미 여러 기관과 조인해 협업 연구를 진행 중이다. 애초부터 합쳐 개발했으면 모를까, 이들 2개 역량을 합친다고 효과가 나올까. 과기정통부는 KIMM과 KIST이 양산하는 데이터 프로토콜을 맞춰 기업에 공개하라는 주문이 최종 목표다. 국가차원서 휴머노이드 연구개발 판 들여다봐야 휴머노이드 개발에서 나오는 데이터를 서로 공유하고, 원팀이 되어 역량을 결집하자는, 명제는 단순하다. 그런데, 이 문제를 풀기 위해서는 부총리급 직위와 역량이 필요해 보인다. 과기정통부나 출연연구기관 뿐만이 아니라 우리나라 로봇 개발 전체의 판을 놓고 들여다봐야 하기 때문이다. KIMM이 주도하는 사업만도 ETRI와 KITECH, KAIST,GIST,서울대, DGIST, 성균관대, DLA,UCLA,뉴욕주립대, MIT, CWU, 에이로봇, 라이온로보틱스, LG전자, 등등 22개 기관으로 구성돼 있다. KIST는 KAIST와 연세대, 고려대, 엔비디아, KITECH, 위로보틱스, DGIST, LG전자, LG이노텍, LG에너지솔류션, 라이온로보틱스 등을 구상 중이다. 이미 판이 벌어졌다. 새로 짜면 모를까, 이미 벌어진 판을 새로 수습하기는 더 어렵다. 배경훈 부총리겸 과학기술정보통신부 장관이 올해 초 업무보고에서 휴머노이드 개발 속도를 강조한 바 있어, 협의체 가동이속도를 낼 것으로는 보인다. 그러나 한편으로는 걱정도 된다. 그동안 정부가 매년 몇 천 억원씩 들여 추진해온 인공지능 학습용 데이터셋 구축사업 성과를 잘 알기 때문이다.