"2030까지 연구생산성 2배로"…K-문샷 민관 원팀 본격 가동
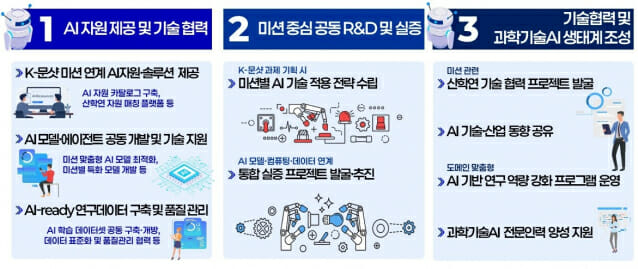
민관이 손잡고, 오는 2030년까지 연구생산성을 2배로 올릴 K-문샷 프로젝트에 시동을 걸고 나섰다. 과학기술정보통신부는 11일 서울 더플라자 호텔에서 국내 AI·인프라 기업 18개와 첨단바이오·소재·미래에너지 등 미션 분야 기업 15개 등 모두 33개 기업과 'K-문샷 추진전략 협력기업 업무협약식'을 체결했다. 'K-문샷 추진전략'은 AI와 과학기술을 융합, 국가 핵심 미션을 해결하고 과학기술 혁신을 가속화하는 범국가 프로젝트다. 오는 2030년까지 연구생산성을 2배로 높이자는 것이 핵심 취지다. 2035년까지는 첨단바이오·소재·미래에너지·피지컬AI 등 8대 분야 12대 국가 미션 해결을 목표로 한다. 이번 협약식은 K-문샷을 구체적으로 이행하기 위한 첫 실행 조치다. 배경훈 부총리를 비롯한 AI·인프라 및 K-문샷 8대 미션 관련 기업 대표 등 50여 명이 참석했다. 참여기업은 ▲ AI 모델·에이전트 분야에서 LG AI 연구원, SKT, 업스테이지, 네이버클라우드, NC AI, 모티프테크놀로지, KT, 포티투마루, 노타, 라이너, 아스테로모프 ▲ 컴퓨팅 인프라 분야에서 LGU+, 엘리스그룹, 망고부스트(데이터 분야) 페르소나AI, 플리토, 메가존, 솔트룩스 등이다. 첨단바이오, 미래에너지, 피지컬AI, 우주, 소재, AI과학자, 반도체, 양자 등 8대 미션 분야에서는 와이브레인, 한국양자산업협회, 한국수력원자력, 심플랫폼, 삼성중공업, 리얼월드, 마음AI, 위로보틱스, 주성엔지니어링, 퓨리오사AI, 성림첨단산업 등 15개 기업이 참여한다. 과기정통부는 협력의사를 밝힌 161개 기업 가운데 AI 모델·컴퓨팅·데이터 등 88개 AI·인프라 기업을 중심으로 'K-문샷 기업 파트너십'을 구축할 계획이다. 파트너십에 참여하는 기업은 △AI 모델 △컴퓨팅·네트워크 △데이터 등 3개 분과로 나눠 AI 자원 제공 및 기술 협력, 공동 연구개발 및 실증, AI 기반 과학기술 생태계 조성 등을 추진한다. 또한, 협력기업을 대상으로 연구데이터·GPU 등 인프라와 후속 사업화 지원 등 다양한 인센티브를 제공할 계획이다. 이날 행사에서는 또 협력기업과 관련 출연연(KIST, ETRI, KISTI) 등이 K-문샷 협력 방안을 논의했다. 이와함께 이날 열린 관학기술관계장관회의에서도 세 번째 안건으로 K-문샷 추진현황이 보고됐다. 이 보고에서는 지난 회의에서 공개된 전략기술 8대 분야 12대 국가 미션 후보안에 대한 협의를 진행, 미션 확정과 함께 소관 부처 참여 및 협력 의사를 확인했다. 또 K-문샷 정책 실행을 위해 우선, 이를 책임질 PD(프로젝트 매니저)를 선임하기로 했다. PD는 미션 로드맵을 완성하고, 내년 신규 R&D 사업 기획 등 예산 작업에 참여한다. 이들은 오는 5월 출범할 범부처 'K-문샷 추진단'을 통해 미션 세부 추진계획을 발표할 예정이다. 배경훈 부총리는 “AI가 단순한 기술 발전을 넘어 과학기술 연구 방식 자체를 근본적으로 재설계하고 있는 지금이 국가 역량을 결집할 골든타임”이라며, “대한민국이 더 이상 기술을 따라가는 나라가 아니라 미래 기술을 선도하는 국가로 도약할 수 있도록, 미지의 우주를 향해 나아갔던 달 착륙선을 준비하는 사명감으로 'AI 아폴로 시대'를 향한 K-문샷을 추진해 나가겠다”고 밝혔다.