[유미's 픽] "연산보다 메모리"…구글 '터보퀀트' 등장에 엔비디아도 '긴장'
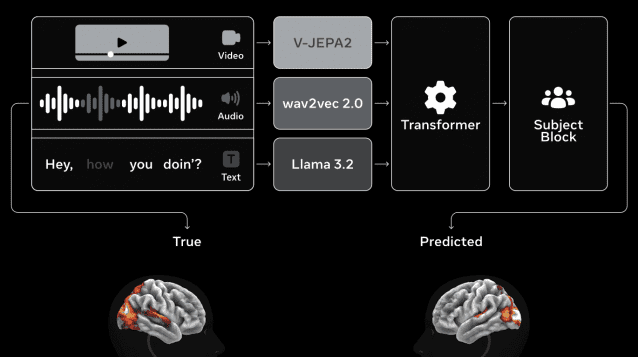
구글이 생성형 인공지능(AI) 운영의 핵심 병목으로 꼽혀온 '메모리 문제'를 소프트웨어 방식으로 풀어내는 기술을 공개하면서 AI 인프라 경쟁의 방향이 바뀌고 있다. 모델 규모 확대 중심이던 기존 경쟁 구도가 실행 효율과 메모리 최적화 중심으로 이동하고 있다는 분석이 나온다. 27일 업계에 따르면 최근 대규모언어모델(LLM) 운영에서는 연산 성능보다 메모리 처리 효율이 전체 성능을 좌우하는 사례가 늘고 있다. LLM은 답변 생성 과정에서 이전 정보를 반복적으로 참조하는 구조를 갖고 있어 데이터 접근 과정에서 발생하는 지연이 속도와 비용을 동시에 제한하는 요인으로 작용한다. 현재 엔비디아 H100 등 최신 그래픽처리장치(GPU) 도입으로 연산 성능은 크게 향상됐지만, 메모리 대역폭과 데이터 이동 효율은 상대적으로 제한돼 있다. 실제 서비스 환경에서는 GPU 연산보다 메모리 접근이 병목으로 작용하는 경우가 적지 않다. 이 같은 흐름 속에서 AI 추론 시스템을 구성하는 기술 구조에 대한 이해도 중요해지고 있다. AI 추론은 모델, 메모리 구조, 실행 소프트웨어, 하드웨어가 단계적으로 결합된 형태로 작동한다. 우선 모델은 연산 과정에서 생성된 정보를 메모리에 저장하고 이를 반복적으로 참조한다. 이 과정에서 메모리 사용량이 급격히 증가하며 병목이 발생한다. 이를 해결하기 위한 접근이 메모리 압축 기술로, 데이터 표현을 줄이는 양자화(Quantization) 방식과 데이터 구조를 효율적으로 인코딩하는 방식이 함께 발전하고 있다. 이 가운데 구글이 지난 24일 공개한 터보퀀트(TurboQuant)는 데이터 표현 방식을 재구성하는 양자화 기반 접근으로, 메모리 사용량을 줄이면서도 정확도를 유지하는 데 초점을 맞춘 기술로 평가받는다. 엔비디아 역시 같은 문제를 두고 다른 접근을 시도하고 있다. 특히 최근에는 KV 캐시를 효율적으로 저장하기 위한 'KV 캐시 트랜스폼 코딩(KV Cache Transform Coding)' 기반 기술을 앞세우고 있다. 이는 데이터를 단순히 제거하는 방식이 아닌, 정보 구조를 효율적으로 인코딩해 저장 효율을 높이는 접근에 가깝다. 다만 모델별 특성에 맞춘 보정 과정이 필요하다는 점에서 적용 방식에는 차이가 있다. 두 기술 모두 메모리 압축을 목표로 하지만 접근 방식에는 차이가 있다. 터보퀀트가 양자화를 기반으로 정확도 손실을 최소화하는 데 초점을 둔 반면, KV 캐시 트랜스폼 코딩은 인코딩 효율을 높여 압축률을 끌어올리는 기술로 분석된다. 두 기술은 기존 메모리 최적화 기술의 연장선에선 의미 있는 진전으로 평가된다. KV 캐시의 정밀도를 낮추는 양자화 기법은 GPTQ, AWQ 등 오픈소스 진영과 스타트업을 중심으로 확산돼 왔고, 중요도가 낮은 토큰을 선택적으로 제거하는 방식이나 슬라이딩 윈도우 기반 메모리 관리 기법도 일부 모델에 적용돼 왔다. 또 메모리 접근을 줄이는 어텐션 최적화 기술은 데이터 전송 횟수를 줄여 속도를 높이는 플래시어텐션(FlashAttention) 등으로 발전하며 주요 AI 기업과 연구 커뮤니티에서 활용되고 있다. 업계 관계자는 "양자화나 토큰 프루닝 같은 기법은 이미 널리 쓰이고 있지만, 실제 서비스에서는 정확도나 안정성 문제 때문에 적용 범위가 제한적인 경우가 많다"며 "KV 캐시 자체를 압축 대상으로 삼는 접근은 구현 난이도는 높지만, 제대로 적용되면 체감 성능을 크게 바꿀 수 있는 영역"이라고 밝혔다. 메모리 압축과 더불어 모델 실행 방식 자체를 개선하려는 소프트웨어 경쟁도 확대되고 있다. vLLM, 텐서RT-LLM(TensorRT-LLM)을 비롯해 라마(llama.cpp) 등 다양한 추론 엔진들이 등장하며 요청 처리 방식과 메모리 관리 효율을 높이는 방향으로 발전하고 있다. 특히 vLLM은 미국 UC버클리 연구진이 주도해 개발한 오픈소스 추론 엔진으로, 요청을 효율적으로 묶어 처리하고 페이지드어텐션(PagedAttention) 구조를 통해 메모리를 동적으로 관리하는 방식으로 처리 효율을 높인다. 엔비디아가 개발한 텐서RT-LLM(TensorRT-LLM) 역시 GPU 연산을 최적화해 추론 속도를 개선하는 소프트웨어로, 데이터센터 환경에서 널리 활용되고 있다. 추론 엔진은 모델 자체를 변경하지 않고도 실행 방식만으로 성능을 개선할 수 있다. 동일한 모델이라도 어떤 실행 소프트웨어를 사용하느냐에 따라 처리 속도와 비용이 달라지는 구조다. 업계 관계자는 "같은 모델이라도 vLLM이나 텐서RT 같은 추론 엔진 설정에 따라 처리량 차이가 크게 난다"며 "실제 서비스에서는 모델보다 실행 스택이 성능을 좌우하는 경우도 적지 않다"고 설명했다. 메모리 압축 기술과 추론 엔진이 결합된 뒤 최종 연산은 GPU에서 수행된다. 특히 최신 GPU 환경에서는 연산 성능보다 메모리 활용 효율이 전체 성능을 좌우하는 경우가 많아지면서 소프트웨어 기반 최적화의 중요성이 더욱 커지고 있다. 이와 함께 AI 경쟁의 방향도 변화하고 있다. 그동안 생성형 AI는 더 많은 데이터를 학습하고 더 큰 모델을 구축하는 데 집중해 왔지만, 최근에는 동일한 모델을 얼마나 빠르고 비용 효율적으로 운영할 수 있는지가 핵심 경쟁력으로 부상하고 있다. 업계 관계자는 "대규모 서비스에서는 모델 성능보다 추론 효율이 비용 구조를 좌우하는 경우가 더 많다"며 "메모리 구조와 추론 엔진을 함께 최적화하지 않으면 GPU를 늘려도 수익성을 맞추기 어려운 단계에 들어섰다"고 말했다.