MS, 멀티모달 AI '플로렌스-2' 출시...음성·비전 통합 처리
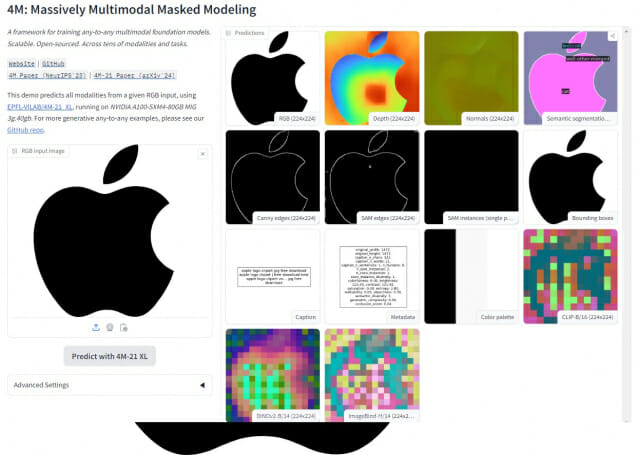
마이크로소프트가 객체감지, 이미지 분석 등 다양한 비전 작업을 한 번에 처리할 수 있는 새로운 비전기반 인공지능(AI)모델을 공개했다. 20일(현지시간) 벤처비트 등 외신에 따르면 마이크로소프트의 애저AI 팀이 새로운 비전 기반 모델 '플로렌스-2'를 허깅페이스를 통해 출시했다고 밝혔다. 플로렌스-2는 시각과 언어를 융합하는 새로운 방식의 기술이 적용된 AI 모델이다. 이를 통해 이미지 캡션 생성, 객체 감지, 이미지 분석 등 다양한 이미지 관련 작업을 통합 수행할 수 있으며 성능도 향상됐다. 이 AI모델은 이미지나 사진 속 내용을 설명하는 문장을 그대로 생성할 수 있으며, 이미지 속에서 특정 객체를 찾아내고, 그 위치를 특정할 수 있다. 예를 들어, 이미지 속에 자동차와 사람, 나무 등이 있다면 각 객체의 위치를 정확하게 파악하는 것이 가능하다. 또한, 이미지와 관련된 질문을 받을 경우 적합한 답변을 제공하는 시각적 질문 응답 (VQA) 기능도 지원한다. 만약 책을 읽고 있는 사람의 사진을 입력한 후 행동을 묻는다면 "책을 읽고 있다"라는 답변을 얻을 수 있다. 이를 활용해 대량의 이미지 콘텐츠에 자동으로 설명을 추가하거나, 전자상거래 플랫폼에서 제품 이미지를 분석하고, 그 특성을 기반으로 한 자세한 설명을 생성할 수 있다. 또한 공공 장소에서 의심스러운 행동을 자동으로 감지하는 등 보안 목적으로 활용하거나, 로봇에 적용해 인간과 자연스럽게 상호작용할 수 있도록 행동을 지원할 수도 있다. 마이크로소프트 측은 플로렌스-2는 복잡한 이미지 관련 작업을 하나의 통합된 시스템 내에서 처리할 수 있도록 설계되어, 이러한 효율적이고 지능적인 이미지 분석이 가능하다고 밝혔다. 성능면에서도 상당부분 개선됐다. 제로샷 성능의 경우 이미지 캡션 생성 모델의 성능을 평가하기 위한 지표인 CIDEr에서 135.6점을 기록하며, 84.3점을 기록한 딥마인드의 플라밍고와 비교해 상당한 차이를 벌렸다. 파인튜닝 성능 역시 대규모 데이터셋 RefCOCO 기반 벤치마크에서 동일 범주 내 다른 경쟁 모델들을 상회하는 성능을 기록했다. 마이크로소프트 측은 언어와 비전이라는 서로 다른 양식(모달리티)을 융합하는 과정에서 몇 가지 어려움이 있었다고 밝혔다. 두 모달리티 간의 복잡한 상호 작용을 처리하기 위해 기존 다양하고 광범위한 데이터를 보유한 데이터셋이 요구됐다. 이에 FLD-5B라는 대규모 데이터셋을 새롭게 구축했다. 이 데이터셋은 5.4억 개의 시각적 주석을 포함하고 있으며, 다양한 시각적 상황과 세부적인 언어적 설명을 결합한 1억2천600만 이미지로 구성되어 있다. 이를 통해 보다 풍부하고 다양한 시나리오에서 비전과 언어의 상호 작용을 학습하는 것이 가능했다. 더불어 비전 데이터와 언어 데이터를 통합하는 과정에서 그 관계와 상황을 이해하기 위해 고도의 언어 이해 능력과 시각적 맥락 분석 기술이 필요했다. 이를 위해 마이크로소프트는 텍스트 프롬프트를 작업 지시로 사용하는 시퀀스-투-시퀀스 아키텍처를 적용했다. 이 구조는 이미지 인코더와 다중 모달리티 인코더-디코더를 통해 비전 토큰과 텍스트 토큰을 통합하여 처리한다. 해당 기술을 적용하면서 플로렌스-2는 이미지 내 객체들의 관계를 비롯해 이미지 속 상황에 대한 세밀한 설명을 생성하는 것이 가능해졌다. 더불어 마이크로소프트는 대규모 이미지와 텍스트 데이터를 처리하는 과정에서 발생하는 막대한 계산비용을 줄이기 위해 최적화된 학습 전략과 하드웨어 효율화 기술을 적용했다. 마이크로소프트 연구팀은 “오늘날 AI 기술 발전에 있어 중요한 것은 다양한 모달리티 간의 경계를 허무는 것”이라며 “플로렌스-2는 이미지와 텍스트 간의 상호 작용을 이해하고 이를 기반으로 새로운 정보를 생성하는 능력을 보유하고 있다”고 설명했다. 이어서 “마이크로소프트는 플로렌스-2를 기반으로 더욱 발전된 모델을 개발해 다양한 AI 응용 분야에 기여할 계획”이라며 “플로렌스-2의 공개는 연구자들과 개발자들에게 새로운 가능성을 제공하며 전 세계적으로 AI 기술의 발전을 지원할 것”이라고 강조했다.