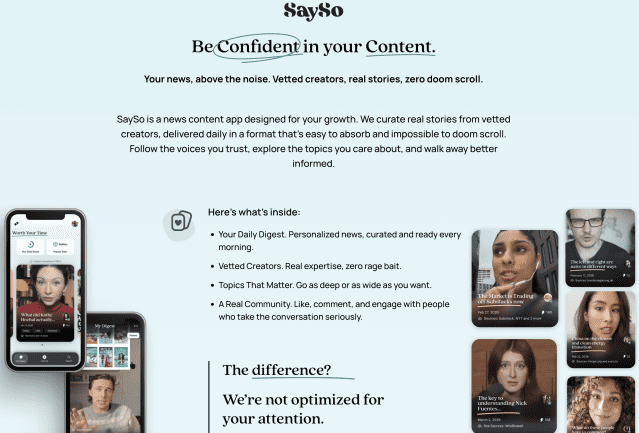
자극적 뉴스는 싫다…'차분한 서재' 꿈꾸는 뉴스 앱들
지구촌을 뜨겁게 달구고 있는 2026 북중미 월드컵의 또 다른 주인공은 '인공지능(AI)'과 '소셜 미디어'다. 국제축구연맹(FIFA)은 일찌감치 틱톡을 동영상 콘텐츠 '우선 플랫폼'으로 선정했다. 이번 계약으로 공식 미디어 파트너들은 틱톡을 통해 경기 일부를 생중계하고 하이라이트 클립을 게시할 수 있게 됐다. 파트너로 선정된 틱톡 크리에이터들은 월드컵 기간 중 기자회견과 훈련 세션 등 현장 접근 권한까지 거머쥐었다. 유튜브 역시 경기 초반 10분 미리보기와 수많은 2차 가공 영상을 쏟아내며 중요한 역할을 하고 있다. 월드컵 특수를 노린 수많은 크리에이터들이 '시선 끌기' 경쟁에 적극적으로 나선 결과다. 이처럼 전통 저널리즘의 영향력이 줄어든 틈을 유튜브와 소셜 플랫폼이 빠르게 메우고 있다. 달라진 지형도는 수치로도 증명된다. 로이터 저널리즘 연구소의 조사에 따르면 전 세계 성인의 27%가 매주 온라인 크리에이터를 통해 뉴스를 소비한다. 하지만 소셜 미디어가 신선한 재미만 선사하는 것은 아니다. 감동적인 경기 하이라이트 사이로 자극적인 짜깁기 쇼츠와 근거 없는 불화설을 담은 '사이버 렉카' 영상이 판을 친다. 조회수만을 노린 자극적인 썸네일과 가짜뉴스가 알고리즘의 파도를 타고 끝없이 밀려든다. 우리는 그 어느 때보다 많은 '뉴스'를 보지만, 역설적이게도 그 어느 때보다 깊은 '피로함'을 느끼게 됐다. 빅테크 플랫폼의 알고리즘은 저널리즘의 가치보다 '이용자의 체류 시간'을 더 중시하기 때문이다. 그들이 자극적이고 확증편향을 유도하는 콘텐츠를 우선 배치하는 이유다. 수용자들의 만족도가 떨어지는 것은 당연한 수순이다. 로이터저널리즘 연구소 조사에서도 크리에이터를 통해 뉴스를 접하는 이들(27%) 중, 정보 욕구가 충분히 충족된다고 답한 사람은 절반(13%)에 불과했다. 둠스크롤링을 거부하는 '세이소'의 당돌한 도전 이러한 디지털 소음과 자극을 걸러내겠다고 선언한 뉴스 앱이 등장해 관심을 끌고 있다. 세로형 동영상 뉴스 앱 '세이소(SaySo)'가 그 주인공이다. 미국의 미디어 전문 매체 니먼랩은 최근 세이소의 신선한 시도를 심층 소개했다. 세이소의 모토는 명확하다. "검증된 크리에이터, 실제 뉴스, 둠스크롤링 제로." 여기서 눈길을 끄는 단어는 단연 '둠스크롤링(Doomscrolling)'이다. 파멸을 뜻하는 '둠(Doom)'과 '스크롤(Scrolling)'의 합성어로, 소셜 미디어에서 자극적이고 부정적인 콘텐츠를 강박적으로 끊임없이 소비하는 행위를 뜻한다. 결국 세이소는 검증된 크리에이터들이 전하는 '진짜 뉴스'를 통해 피드 위의 둠스크롤링을 추방하겠다는 포부를 밝힌 셈이다. 이들은 거대 플랫폼처럼 알고리즘의 덫으로 이용자를 묶어두려 하지 않는다. 대신 철저하게 검증한 소수의 크리에이터만을 무대에 세운다. 영상이 공개되기 전, 모더레이터가 내용을 직접 검토하는 강력한 '안전장치'까지 마련했다. 당일의 주요 뉴스를 정돈해 보여주는 '다이제스트(Digest)' 탭은 이용자에게 “이제 스마트폰을 내려놓고 일상으로 돌아가라”고 다정하게 속삭이는 듯하다. 지난 4월, 세이소는 30명의 뉴스 크리에이터들과 함께 첫발을 디뎠다. 방송 기자 출신 기후 전문가 리아 뉴먼, 정치 시사 분석 팟캐스트 '메이크 잇 메이크 센스'의 운영자 그랜트 헤르메스 같은 스타 크리에이터들이 힘을 보탰다. 세이소는 올해 말까지 참여 크리에이터를 70명 수준으로 늘릴 계획이다. 객관성을 바라보는 이들의 관점도 흥미롭다. 세이소는 “완벽하게 객관적인 뉴스란 불가능하다”고 솔직하게 고백한다. 대신 “크리에이터가 자신의 관점과 출처를 투명하게 밝히는 것이 오히려 더 공정하다”고 믿는다. 시끄러운 광장 대신 '차분한 서재'를 응원하며 이런 시도를 하는 것이 세이소만은 아니다. 구독 기반의 독립 저널리스트 플랫폼 '뉴스피어(Noosphere)'나, 기자가 쓴 뉴스를 스와이프 카드로 읽는 '뉴스릴(Newsreel)' 같은 앱들도 비슷한 기치를 내걸고 있다. 이들은 모두 거대 플랫폼의 '에코 체임버(Echo Chamber·확증편향 현상)'에 지친 독자들에게 '시끄러운 광장' 대신 '차분한 서재'를 제공하겠다는 공통된 지향점을 지닌다. 물론 빅테크가 구축한 철옹성 같은 장벽을 넘기란 결코 쉽지 않을 것이다. 크리에이터들에게 안정적인 수익을 보장할 만큼 대중적인 인기를 끌기까지는 수많은 난관을 마주해야 할지도 모른다. 그럼에도 불구하고 이 시끄러운 시대에 등장한 작고 정돈된 실험들을 진심으로 응원한다. 자극적인 폭로와 조회수 경쟁이 저널리즘의 전부가 되어서는 안 되기 때문이다. 뉴스를 읽는 행위가 스트레스가 아니라 지적인 충족감이 되는 세상, 조금은 무모하고 당돌해 보이는 세이소의 시도에 박수를 보내는 이유다. 이들의 묵묵한 도전이 의미 있는 성과로 이어져, 탁한 미디어 생태계에 꼭 필요한 산소이자 저널리즘의 새로운 이정표가 되어주기를 기대해 본다.