[유미's 픽] "실적 새 역사 또 썼다"…현신균號 LG CNS, 매출·영업익 6년 연속 역대 최대
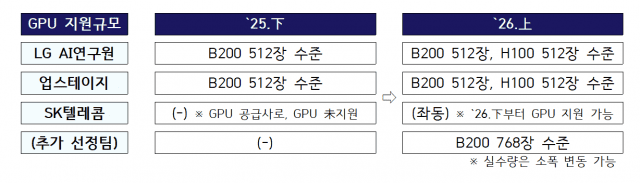
사장 승진 1주년을 맞은 현신균 LG CNS 대표가 지난해 기업공개(IPO)를 성공적으로 이끈 데 이어 또 다시 실적 경신에 성공하며 실력을 입증했다. 금융·공공 부문의 인공지능 전환(AX) 수주 잔고가 실제 수익으로 연결되기 시작한 데다 고객 맞춤형 인공지능(AI) 적용 사례가 늘어나며 AX 전문 기업으로도 입지를 확고히 한 모습이다. 27일 금융감독원 전자공시시스템에 따르면 LG CNS의 지난해 연결 기준 매출은 전년 동기 대비 2.5% 증가한 6조1천295억원을 기록했다. 같은 기간 영업이익은 1년새 8.4% 상승한 5천558억원, 영업이익률은 전년 대비 0.5%포인트(p) 증가한 9.1%로 집계됐다. 당기순이익도 현금성 자산 증가로 인한 순이익수익 확대, 투자수익 관련 이익 증가 영향 덕분에 전년 같은 기간보다 21.2% 늘어난 4천421억원으로 마무리됐다. 연간 매출이 6조원을 넘어선 것은 이번이 처음으로, 사상 최대치를 기록했다. 또 핵심 성장 동력인 AI와 클라우드 분야에서 선전한 덕분에 매출, 영업이익 모두 6년 연속 최대 실적 경신이란 기록 달성에도 성공했다. 다만 매출은 시장 컨센서스(6조3천291억원)에 다소 못미쳤고, 영업이익(5천548억원)은 비슷한 수준을 기록했다. 이에 대해 LG CNS 관계자는 "AI 분야에서 금융, 제조, 공공 등 다양한 산업 전반에 걸쳐 업계 최다 수준의 대외 고객을 확보하며 AX 사업을 확장 중"이라며 "에이전틱 AI 풀스택 플랫폼 '에이전틱웍스(AgenticWorks)'를 활용한 사업을 본격화하는 한편, 글로벌 클라우드 3사의 AI 서비스를 적용한 AX 사업도 활발히 전개하며 국내 AX 사업 주도권을 공고히 하고 있다"고 설명했다. 이 같은 호실적은 AI와 클라우드 분야 덕분으로, 전체 실적 상승을 이끈 것으로 분석됐다. 이 분야의 연간 매출은 3조5천872억원으로, 전년 대비 7.0% 성장한 모습을 보였다. 이는 LG CNS가 한 해 동안 클라우드 분야에서 다양한 성과를 나타낸 것이 주효했다. 이곳은 국내 최초로 데이터센터 DBO(Design, Build, Operation) 사업을 시작한 이래 성과를 꾸준히 창출하며 업계를 이끌고 있다. 또 최적의 설계·구축·운영 역량, 고효율 냉각솔루션, 첨단 전력 시스템 등 LG의 핵심 역량을 결집한 '원(One) LG' 솔루션을 기반으로 AI 데이터센터 경쟁력을 강화하며 글로벌 AI 데이터센터 시장 공략도 가속화하고 있다. 이를 위해 LG전자의 데이터센터 냉각 기술, LG에너지솔루션의 배터리 솔루션 등 그룹 내 핵심 역량까지 끌어들였다. 특히 지난해 8월에는 국내 기업 최초로 해외에서 AI데이터센터 구축 사업을 맡았다는 점에서 긍정적인 평가가 많다. LG CNS는 인도네시아 수도 자카르타에 약 1천억원 규모의 초거대(하이퍼스케일급) AI데이터센터를 올해 말까지 완공할 계획으로, 이를 위해 현지 재계 서열 3위인 시나르마스 그룹과 손잡고 합작법인까지 설립했다. 여기에 최근에는 정부 주도 사업인 '독자 AI 파운데이션 모델 프로젝트'의 중심축으로도 급부상하며 시장의 기대감을 한 몸에 받고 있다. LG CNS는 1차 평가를 통과한 LG AI연구원 컨소시엄에 참여해 파인튜닝 방법론 개발, 데이터 수집 및 정제 등의 역할을 맡고 있는 상태로, 이 컨소시엄은 'K-엑사원'으로 평가 종합 1위를 기록했다. 덕분에 이후 주가는 꾸준히 상승해 평가 발표 전날인 이달 14일 종가(6만1천800원) 대비 이날 오전 10시 5분 현재 주가(7만2천원)은 약 16.5% 증가했다.업계 관계자는 "'K-엑사원'이 최종 국가대표 AI 모델로 선정될 경우 LG CNS는 장기 수혜 가능성이 크다"며 "향후 정부가 추진하는 AX 사업에서 유리한 고지를 선점할 수 있다"고 전망했다. 정원석 신영증권 연구원은 "이번 프로젝트를 통해 엑사원 모델의 성능이 개선되고 신뢰도가 상승할 경우 LG CNS의 AI 솔루션에 대한 수요가 증가할 가능성이 있다"며 "특히 공공 프로젝트 수주에도 유리할 것으로 예상된다"고 말했다. 하지만 AI·클라우드 사업과 달리 주요 사업의 또 다른 축인 스마트엔지니어링, 디지털비즈니스 분야에선 다소 주춤한 모습을 보였다. 스마트엔지니어링 분야의 연간 매출은 1조1천935억원을 기록했으나, 전년 동기 대비 3.5% 하락해 아쉬움을 남겼다. 매출 인식 시점이 다소 늦어지는 사업 구조 특성과 시장 수요 둔화, 경쟁 입찰로 인한 수익성 압박, 성장 리소스가 AI·클라우드 쪽에 더 집중된 것이 복합적으로 작용한 탓이다. 하지만 지난해 상반기에 비해 하반기로 갈수록 스마트물류 사업이 뷰티·푸드·패션·방산 분야로 포트폴리오를 확장한 데다 해외에 진출한 국내 기업의 물류 자동화 사업도 수주하는 등 글로벌 시장 확대를 위한 기반을 마련해 하락폭을 둔화시켰다. LG CNS 관계자는 "스마트팩토리 사업은 방산·반도체·제약 분야에서 수주한 프로젝트를 안정적으로 수행 중"이라며 "중소·중견 제조기업을 위한 경량형 스마트팩토리 솔루션 판매도 확대하고 있다"고 설명했다.디지털 비즈니스 서비스 부문의 연간 매출도 1년 새 3.2% 하락한 1조3천488억원으로 집계됐다. 이는 전통적인 시스템 통합(SI)·운영(SM) 중심의 디지털 서비스 수요 둔화 때문으로, 기업과 공공 부문의 대형 시스템 구축·운영 프로젝트가 일부 지연되면서 매출 인식 시점이 뒤로 밀렸기 때문으로 분석된다. 또 고객사의 IT 투자 방향이 기존 SI 중심에서 AI·클라우드·데이터 기반 사업으로 빠르게 이동한 점도 영향을 미친 것으로 보인다. 업계 관계자는 "LG CNS 내부적으로도 성장성이 높은 AI·클라우드 사업에 전략적 자원을 집중한 것으로 보인다"며 "이 탓에 디지털 비즈니스 서비스 부문의 상대적 매출 비중이 줄어드는 구조가 나타났다"고 분석했다. 하지만 LG CNS는 지난해 한국예탁결제원, 미래에셋생명보험, NH농협은행 등 대형 금융 IT 사업을 수주하며 위기 타개에 적극 나섰다. 에이전틱 AI로 진화하는 IT 서비스 시장 변화에 맞춰 AI 기반 개발 방식을 적극 도입하며 SI와 SM 역량을 지속 강화하려는 모습도 보였다. 특히 '프로젝트 한강'의 주사업자로 나서며 경쟁력도 입증했다. 이곳은 지난해 말 한국은행과 국내 최초로 '에이전틱 AI 기반 디지털화폐 자동결제 시스템'을 실증하며 차세대 결제 인프라 구현에 성과를 냈다. 또 최근에는 토큰증권과 스테이블코인 관련 사업도 활발히 전개하며 시장의 기대감을 높이고 있다. 김준성 KB증권 연구원은 "LG CNS는 지난해 말 NH농협은행의 차세대 시스템 구축 프로젝트를 수주했다"며 "단일 계약 기준 최대 규모로 알려져 있고 2028년 4월까지 사업이 진행될 예정"이라고 설명했다. 이어 "정부의 AI 예산이 전년 대비 3배 확대되는 등 금융권을 중심으로 AX 수요가 급증하고 있다"며 "LG CNS의 AX 프로젝트 이력이 대형 수주에 긍정적으로 작용했을 것"이라고 덧붙였다. 이 같은 상황 속에 LG CNS는 올해 국내 AX·RX(로봇 전환) 선도 사업자로서의 입지를 한층 강화해 또 다시 실적 경신에 도전한다는 방침이다. 에이전틱 AI 분야에서는 에이전틱웍스 플랫폼에 탑재 가능한 산업별·업무별 특화 에이전트를 추가 개발하고 코히어, 오픈AI 등 글로벌 빅테크와의 협력을 통해 AX 시장 영향력을 확대한다는 전략이다.업계 관계자는 "LG CNS는 글로벌 빅테크의 AI 모델과 자사 AX 플랫폼을 결합해 고객 맞춤형 AI 서비스 구현 역량을 고도화하고 있다"며 "덕분에 단순 SI를 넘어 AI 서비스 사업자로의 전환 속도를 높이고 있다"고 평가했다. 미래 성장 동력으로는 피지컬 AI 사업을 전략적으로 추진하고 있다. 로봇 파운데이션 모델(RFM)을 활용해 산업 현장 데이터를 기반으로 로봇 동작을 파인튜닝하고, 자체 로봇 통합 운영 플랫폼을 확보해 RX(로봇 전환) 역량을 강화하고 있다. 현재 10여 개 고객사의 물류센터와 공장에서 로봇 업무 수행 개념검증(PoC)을 진행 중으로, 산업용 휴머노이드 로봇의 현장 적용도 준비하고 있다. 글로벌 시장 공략도 확대한다. 물류·제조 AX 사업은 북미 지역에서 계열사 공장의 완전 자동화를 위한 로봇 도입을 확대하고 있다. 또 데이터센터 사업은 국내 기업 최초로 해외(인도네시아) AI 데이터센터 구축 사업을 수주해 베트남 등으로 확장을 준비하고 있다. K-뱅킹 시스템을 인도네시아·싱가포르 등 아태 지역으로 수출하는 글로벌 금융 사업도 본격 확대하고 있다. 성장 전략의 한 축인 인수·합병(M&A)도 올해 성사시킬지 주목된다. 현 대표는 지난해 상장에 앞서 열린 기자간담회에서 M&A에 대한 질문에 "전략적인 이유로 구체적으로 밝힐 순 없지만, 가까운 시일 내에 깜짝 뉴스가 나올 수 있을 것"이라고 언급한 바 있다. 또 상장을 통해 약 6천억원의 투자 자금을 확보한 상태로, 보유한 현금성 자산도 있어 적극적인 투자가 가능하다는 점도 공개했다. 하지만 LG CNS는 지난해 유의미한 M&A 성과를 드러내지 못했다. 이를 두고 현 대표는 이달 초 진행한 기자간담회에서 "M&A는 결혼과 비슷하다"며 "서로의 의지가 맞아야 하고 고려해야 할 요소가 많다"고 비유했다. 그러면서 "전략적으로 한 개의 기업이 아닌 여러 분야의 여러 기업과 M&A를 추진하고 있고, 인올가닉 그로스(인수합병·지분투자·전략적 제휴 등 외부 자원을 활용해 빠르게 성장하는 방식)를 위한 M&A도 지속 추진 중"이라고 부연했다. 현 대표는 지난해 사업 성과에 대해서 만족감을 드러내며 올해도 성장세를 이어가겠다는 의지도 밝혔다. 또 올해 목표에 대해 구체적인 수치를 제시하지 않았지만, 방향성은 분명하게 밝혔다. 현 대표는 "항상 성장해야 한다"며 "숫자를 앞세우기보다 실제 성과로 시장의 평가를 받겠다"고 말했다. 시장에선 LG CNS의 올해 실적을 두고 일찌감치 기대감을 드러냈다. 신성장 동력으로 LG CNS가 로봇 전환(RX) 전략을 제시한 것도 긍정적으로 평가했다. KB증권은 "SI 사업자들이 피지컬 AI를 새로운 성장 축으로 접근하는 가운데 LG CNS는 로봇의 '지능'과 '관제'를 담당하는 소프트웨어 전략을 강조하고 있다"며 "산업용 로봇에 중국산 하드웨어와 AI 소프트웨어를 결합해 고부가가치를 창출하는 전략을 추진할 것"이라고 설명했다. 이어 "CES 2026에서 휴머노이드 로봇 보급이 화두로 부각된 가운데 LG CNS와 미국 로봇 기업 스킬드 AI와의 협업도 주목된다"고 덧붙였다. 그러면서 "LG CNS의 투자 포인트는 향후 5년간 연평균 13% 수준의 영업이익 성장에 있다"며 "클라우드·AI 사업 부문의 고성장과 함께 '피지컬 AI'와 같은 신성장 동력이 기업가치를 뒷받침하고 있다"고 강조했다.