[종합] 모티프 합류한 독파모 2차전, 8월에 결판…독자성·데이터 활용성 '관건'
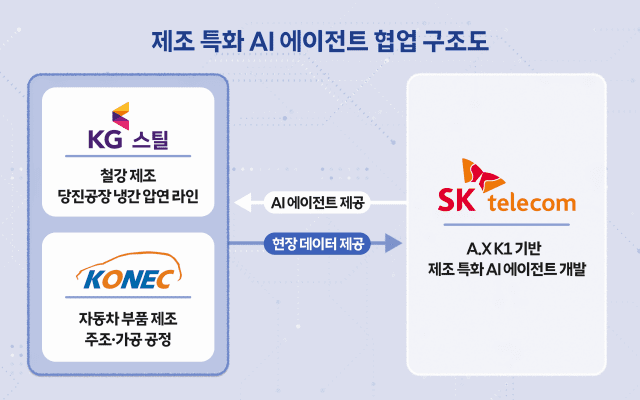
정부가 추진 중인 '독자 AI 파운데이션 모델(독파모, K-AI)' 프로젝트의 추가 정예팀으로 모티프테크놀로지스가 선정되면서 3개 자리를 둘러싼 2차전의 본격적인 막이 올랐다. 이번 경쟁이 대기업 2곳과 스타트업 2곳 구도로 재편된 가운데 2차 평가에서 정부가 어떤 기준을 내세울지, 모티프테크놀로지스가 기존 정예팀과 달리 어떤 전략으로 실력을 드러낼 수 있을지 관심이 집중된다. 20일 과학기술정보통신부에 따르면 모티프테크놀로지스는 트릴리온랩스를 제치고 기존 LG AI연구원, 업스테이지, SK텔레콤에 이어 2차 평가에 도전할 네 번째 'K-AI' 정예팀으로 이날 선정됐다. 독자 아키텍처로 AI 모델을 설계한 경험, 상대적으로 적은 파라미터와 제한된 데이터 환경에서도 세계적인 수준의 모델과 경쟁 가능한 성능을 달성한 경험에서 높은 평가를 받은 것으로 알려졌다.지난해 2월 설립된 모티프테크놀로지스는 반도체 기업 모레 자회사로, 고성능 대형언어모델(LLM)과 대형멀티모달모델(LMM) 모두를 파운데이션 모델로 개발한 경험을 갖췄다. 특히 지난 해 11월 공개한 LLM '모티프 12.7B'는 모델 구축부터 데이터 학습까지 전 과정을 직접 수행한 순수 국산 기술이란 점에서 주목받았다. 또 기존 트랜스포머 구조를 그대로 쓰지 않고 '그룹별 차등 어텐션(GDA)' 기술을 자체적으로 개발·적용해 경쟁력이 있다고 평가 받는다. 모티프테크놀로지스는 정예팀으로 모레, 크라우드웍스, 엔닷라이트, 서울대학교 산학협력단, 한국과학기술원(KAIST), 한양대학교 산학협력단, 삼일회계법인, 국가유산진흥원, HDC랩스, 매스프레소, 에누마코리아, 경향신문사, 전북테크노파크, 모비루스, 엑스와이지, 파두 등을 포함시켰다. 또 300B급 추론형 LLM(거대언어모델)을 시작으로 310B급 VLM(비전언어모델), 320B급 VLA(비전언어액션모델) 등으로 고도화해 독자 AI 파운데이션 모델을 개발·확보하겠다는 목표를 세웠다. 임정환 모티프테크놀로지스 대표는 "그동안 부족한 자원에도 불구하고 독자적인 설계로 글로벌 경쟁력을 증명해왔다"며 "이번 사업에서 지원되는 자원과 컨소시엄의 역량을 결합하면 기존 참가팀을 뛰어넘는 성과를 낼 수 있다고 확신한다"고 말했다. 이어 "모델과 SW를 아우르는 폭넓은 오픈소스화로 국산 AI 생태계를 구축할 것"이라며 "산업·공공 전 분야에서 AX 성공 사례를 만들어 대한민국이 AI G3로 도약하는 데 기여하겠다"고 덧붙였다. 업계에선 모티프테크놀로지스가 독파모 2차전 마지막 정예팀으로 합류하면서 대기업 2곳, 스타트업 2곳이라는 이상적인 밸런스로 경쟁 구도가 갖춰졌다고 평가했다. 자본과 인프라를 갖춘 대기업의 안정감에 속도감 있고 혁신 지향적인 스타트업의 패기가 더해지며 국가 AI 프로젝트가 한층 역동적으로 추진될 것이란 기대감도 내비쳤다. 또 정부가 기존 업체들과의 형평성을 맞추기 위해 모티프테크놀로지스에 전폭적인 지원에 나섰다는 점에서 얼마나 기술 격차를 줄여나갈 수 있을지를 두고 주목하고 있다. 정부는 모티프테크놀로지스에 독자 AI 모델 개발에 필요한 엔비디아 최신 그래픽처리장치(GPU) B200만 768장을 지원할 예정으로, H100과 B200을 함께 공급받는 LG AI연구원, 업스테이지에 비해 모티프테크놀로지스가 좀 더 유리한 고지에 오른 것으로 보인다. 개발 기간도 모티프테크놀로지스에 불이익이 없도록 형평성을 맞췄다. 정부는 기존 3개 정예팀은 1월부터 6월 말까지 AI 모델을 개발하고, 모티프테크놀로지스는 2월부터 7월 말까지 개발할 수 있도록 기간을 정했다. 또 모든 정예팀이 AI 모델 개발을 마친 이후 8월 초 내외에 단계 평가를 진행키로 했다. 데이터 지원은 기존 업체와 동일하게 진행된다. 정부는 데이터 개별 구축·가공에 17억5000만원, 데이터 공동구매·활용에 100억원 수준을 모티프테크놀로지스에 지원하고 'K-AI 기업' 명칭도 부여키로 했다. 업계 관계자는 "모티프테크놀로지스가 트릴리온랩스보다 기술력이 조금 더 있다고 평가돼 추가 사업자로 선정은 됐지만, 기존 3개 업체들과 이미 경쟁해 한 번 탈락했던 상황에서 이번 정부 지원으로 얼마나 격차를 좁힐지가 관건"이라며 "기존 3개 업체들이 단계평가 전 한 달의 시간 동안 미리 3차 평가 준비에 나설 가능성이 높다는 점도 고려할 부분"이라고 말했다. 일각에선 모티프테크놀로지스의 합류로 업스테이지가 제일 긴장감이 높을 것으로 예상했다. 같은 스타트업인데다 모티프테크놀로지스와 달리 업스테이지가 B200을 온전히 지원 받지 못한다는 점에서다. 또 모티프테크놀로지스가 300B급 추론형 LLM을 2차 평가 목표로 내세운 것이 200B 모델을 앞세운 업스테이지를 겨냥한 것이란 평가도 나왔다. 업계 관계자는 "모티프테크놀로지스 입장에선 일단 GPU를 정부 지원으로 돌려 글로벌 수준의 AI 모델 개발에 도전할 수 있고, 인지도도 높일 수 있다는 점에서 엄청난 기회를 잡은 것이라고 보여진다"며 "업스테이지를 넘어설 목표로 2차 평가전에 나설 가능성이 높다"고 밝혔다. 이 같은 상황에서 정부는 정예팀들과 2차 평가 기준·방안 등을 조만간 협의·확정해 글로벌 수준의 독자 AI 파운데이션 모델 개발을 뒷받침하고, 이를 통해 우리나라 AI 생태계 경쟁력 제고 등을 적극 도모한다는 계획을 내놨다. ▲벤치마크 평가 ▲전문가 평가 ▲사용자 평가 등 기존 단계평가의 큰 틀은 유지하되, 글로벌 주요 리더보드 타겟으로 글로벌 벤치마크를 선정하고 전문가 평가 항목에 '독자성' 평가 세분화 등도 검토키로 했다. 또 재공고 시행 배경이 된 개발 모델의 독자성 잣대는 '초기 데이터 로그 보유 및 자체 문제해결 능력'으로 규정해 논란을 불식시키기 위한 노력에도 나섰다. 업계에선 2차 평가 핵심으로 단순한 성능 고도화를 넘어 산업 현장 적용을 위한 '확장성 및 활용성'이 될 것이라고 예상했다. 또 최근 정부가 공공 데이터 개방에 적극 나서고 있는 만큼 데이터를 AI 모델로 얼마나 잘 활용할 수 있을지도 관건이 될 것으로 전망했다. 업계 관계자는 "2차 평가 기준이 1차 때랑 크게 바뀌지 않을 듯 해 모티프테크놀로지스가 기존 3사와의 기술 격차를 어떻게 좁힐 수 있을지가 관건"이라면서도 "정부가 2차 평가에선 컨소시엄에 참여한 기업들과 주관사가 AI 모델 개발 과정에서 어떻게 구체적으로 협업할 수 있는지가 주요 기준이 될 것"이라고 예상했다. 그러면서 "AI 모델 개발에서 끝나는 게 아니라 각 컨소시엄들이 현장에서 어떻게 활용할지에 대한 계획을 잘 드러내는 것이 중요해보인다"고 덧붙였다. 또 다른 관계자는 "정부가 개방한 공공 데이터를 AI 모델을 학습할 때 잘 활용해 우리나라에 특화된 AI로 얼마나 잘 만들 수 있는지가 2차 평가에서 중요하게 반영될 것"이라며 "모델 성능이나 크기보다 데이터 활용도, 우리나라 상황과 한국어 맥락에 맞는 답변을 제대로 내놓을지에 대한 평가가 좀 더 심도있게 진행될 듯 하다"고 전망했다.