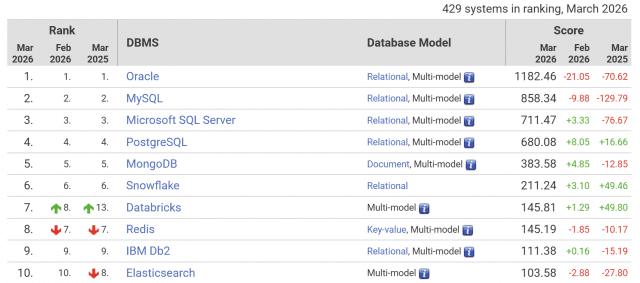
산업용(을) 전기요금 1kWh당 평균 15.4원 인하…기업 97% 혜택
계약 전력 300kW 이상인 산업용(을) 전기요금이 4월 16일부터 1kWh 당 15.4원 인하된다. 지난해 전력소비데이터를 기준으로 했을 때 산업용(을)을 적용받는 기업 97%에 해당하는 3만8000 여개사가 혜택을 받을 전망이다. 기후에너지환경부와 한국전력은 13일 전기위원회 심의를 거쳐 이같은 내용을 담은 '계절·시간대별 전기요금 개편안'을 공개했다. 개편안은 전력 공급능력이 증가하는 낮시간 요금을 낮추고 상대적으로 수요가 상승하는 저녁·심야 시간 요금은 높여, 낮시간대로 전력 소비를 유인하는 것이 골자다. 개편안은 전기요금에 반응해 수요 조정이 상대적으로 용이할 수 있는 산업용(을) 소비자에 집중해 설계됐다. 내용는 ▲시간대별 구분 기준 변경 ▲시간대별 단가 조정 ▲봄·가을 주말 할인 등 3가지 내용으로 구성됐다. 평일 전기요금 시간대 구분 기준이 달라진다. 낮시간대로 요금이 가장 높았던 11~12시와 13~15시 구간이 중간요금(중간부하)으로 조정되는 대신, 화석연료 발전 가동이 증가하는 저녁 18~21시는 중간요금에서 최고요금(최대부하)으로 변경된다. 9시부터 15시까지 낮 시간대 요금이 중간요금(중간부하)으로 통일돼 소비자들이 한층 수월하게 전력 사용량을 계획하고 조절할 수 있을 것으로 기대된다. 최저요금(경부하, 주로 밤)은 1kWh 당 5.1원 인상하고, 최고요금은 여름·겨울철과 봄·가을철 각각 16.9원과 13.2원 인하한다. 평균 15.4원 인하한다. 출력제어가 가장 빈번하게 발생하는 봄(3~5월)·가을(9~10월) 주말과 공휴일 11~14시에는 요금을 50% 할인한다. 개편안은 2030년 12월 31일까지 약 5년간 운영된다. 산업계 수요 이전 참여도 등에 따라 연장을 검토할 수 있는 근거를 함께 마련했다. 수요 부족 상황에서 전력 소비를 증가시킨 만큼 보상하는 '플러스 수요관리제도(DR)'와 동시에 적용받으면 평일 최고요금의 20%~30% 수준인 1kWh당 31~50원에 전력을 구매할 수 있다. 산업용(을) 적용 소비자 요금 개편안은 4월 16일부터 적용된다. 다만, 변경된 요금체계에 맞춰 조업을 조정하려면 추가 준비기간이 필요할 수 있다는 산업계 의견을 반영해 적용 유예를 신청하면 9월 30일까지 추가 준비기간을 부여할 계획이다. 유예신청은 23일부터 접수한다. 시간대별 구분 기준 조정은 산업용(을) 외에도 산업용(갑)Ⅱ(계약전력 4kW 이상 300kW 미만), 일반용(갑)Ⅱ(계약전력 300kW 미만), 일반용(을)(계약전력 300kW 이상), 교육용(을)(계약전력 1,000kW 이상) 등 계절·시간대별 요금이 적용되는 다른 종별에도 공통적으로 적용된다. 준비기간 확보 필요성과 여름철 냉방수요 증가 등을 종합적으로 고려해 6월 1일부터 개편안을 적용한다. 전기자동차 충전전력요금은 전력소비 조정이 상대적으로 용이할 수 있는 점을 반영해 시간대별 구분 기준 조정과 동시에 산업용(을)에 적용되는 봄·가을 주말·공휴일할인(11~14시 50% 할인)이 함께 적용될 예정이다. 한편, 2025년 전력 소비 데이터를 기준으로 분석한 결과, 산업용(을)을 적용받는 기업의 약 97%에 해당하는 3만8000 여개사(사업장 기준)가 요금이 하락할 것으로 분석된다. 산업용(을) 평균적으로는 1kWh 당 약 1.7원 하락하며, 365일·24시간 전력 소비가 동일한 경우 약 1.0원 하락할 것으로 분석된다. 주간 조업 비중이 높은 중소기업(2.7원 하락)이 대기업(1.1원 하락)보다 요금 하락 효과가 상대적으로 더 클 것으로 분석되며, 주말·심야 등 근무 없이 평일 9시~18시에만 조업하는 기업은 16~18원 인하 효과가 기대된다. 기후부 관계자는 “기업의 수요이전 노력에 따라 요금 하락폭은 더 커질 수 있으며, 특히 요금제 개편 이후 최고요금이 적용되는 평일 저녁(18~21시) 대신 50% 요금 할인이 적용되는 주말 낮(11~14시) 시간으로 조정하면 요금 할인 효과가 커질 것”이라고 설명했다. 소상공인의 상당수는 계절·시간대별 요금이 적용되지 않는 소규모 전기 사용자에 해당해 개편안 영향이 제한적이고 일반용·교육용 요금은 시간대별 요금이 적용되는 소비자들은 평균 1원 미만 수준에서 요금이 하락할 것으로 분석된다. 개편안의 상세 내용은 오는 16일부터 한전 공식 누리집, 한전온, 파워플래너 누리집과 모바일 앱 등에서 확인할 수 있다. 이날 전기위원회에서는 지난 12월에 발표한 '히트펌프 보급 활성화 방안'에 따른 주택용 히트펌프 요금 적용기준 개선안도 심의됐다. 주택용 누진 요금 적용에 따른 소비자 우려를 고려해 주택용 히트펌프 이용 소비자는 3가지 중 유리한 요금제를 선택할 수 있게 했다. 우선 소비자 희망에 따라 현행 주택용 누진 요금은 그대로 적용 가능하다. 자가용 태양광을 함께 설치한 경우 등에는 해당 요금이 유리할 수 있다. 또 주택용 누진 요금을 적용하되, 히트펌프 가동에 사용된 전력만 별도로 분리해 일반용 요금(누진제 미적용)을 적용받을 수 있다. 지열 설비는 기존에도 일반용 요금을 적용받을 수 있었으나, 최근 재생에너지로 인정된 공기열 설비까지 적용 대상을 확대했다. 히트펌프가 설치된 주택은 현재 제주에만 적용되는 주택용 계절·시간대별 요금을 육지에서도 선택할 수 있도록 개선했다. 변경된 요금체계는 다음 달 1일부터 시행된다. 재생에너지에 해당하는 지열이나 공기열 설비로 인증된 제품을 설치한 가구를 대상으로 적용된다. 다만, 공기열 설비 인증기준이 마련되지 않은 상황이기 때문에 기후부에서 추진할 '난방전기화 보급 사업' 지원 대상으로 선정된 제품에 대해 개정 기준이 한시적으로 적용될 예정이다. 정부는 송전비용·균형성장 등을 고려해 지역 기업 부담을 완화할 수 있는 방향으로 '지역별 전기요금' 도입도 추진할 계획이다.